Warum Standard-KI an Produktionsrealität scheitert – und spezialisierte Ansätze den Unterschied machen.
von Patrick Kraus-Füreder und Markus Steindl
KI ermöglicht neue Formen der automatisierten Qualitätssicherung – mit enormem Potenzial, aber auch praktischen Hürden in Bezug auf Datenverfügbarkeit, Modellarchitektur und Systemintegration.
Inhalt
Zwischen Alltag und Industrie: Warum generische KI versagt
Bildanomalien: Visuelle Auffälligkeit vs. semantischer Fehler
Supervised oder Unsupervised?
Gelabelte Daten: Der Engpass der Praxis
Variabilität als Realität – und Herausforderung
Adaptivität als Schlüssel zur Zukunft
Hardwareanforderungen im Echtbetrieb
RISC als Lösungspartner: Von der Modellarchitektur zur operativen Umsetzung
Fazit
Sechs Fragen, die sich Unternehmen vor dem Einsatz von Anomalieerkennung stellen sollten
Kontakt
Autoren
Weiterlesen
Zwischen Alltag und Industrie: Warum generische KI versagt
Die meisten vortrainierten Computer-Vision-Modelle aus dem Open-Source-Bereich oder von Forschungseinrichtungen basieren auf Bilddatenbanken wie ImageNet, COCO oder OpenImages. Diese enthalten Millionen von Aufnahmen, jedoch fast ausschließlich aus alltäglichen Kontexten – etwa Autos, Menschen, Tiere oder Möbelstücke. Spezifische industrielle Szenarien, wie sie in der Fertigung auftreten, sind darin kaum oder gar nicht vertreten und lassen sich damit nur unzureichend abbilden. Für den Einsatz in der Industrieproduktion sind diese Daten daher nur eingeschränkt nutzbar.
Die Folge: Ein Modell, das zuverlässig zwischen Hund und Katze unterscheidet, versagt oft vollständig, wenn es die Qualität einer Steckverbindung beurteilen oder feine Risse auf einer hochreflektierenden Metalloberfläche erkennen soll. Die visuellen Merkmale, die industrielle Anomalien definieren, sind schlicht andere – oft subtiler, spezifischer und kontextabhängiger.
Abbildung 1: Beispiele industrieller Anomalien an metallischen Verbindungselementen (Einschlagmuttern). Links: Originalaufnahmen, rechts: markierte Schadstellen. Solche subtilen, kontextabhängigen Defekte lassen sich mit generisch vortrainierten KI-Modellen nur unzureichend erfassen.
Bildanomalien: Visuelle Auffälligkeit vs. semantischer Fehler
Anomalien in industriellen Bilddaten sind nicht nur selten – sie sind auch vielgestaltig. Grob lassen sie sich in zwei Klassen einteilen:
Strukturelle Anomalien: Hierbei handelt es sich um lokale, meist textur‐ oder pixelbasierte Abweichungen, die in ihren charakteristischen Mustern „neu“ gegenüber den Trainingsdaten sind. Typische Beispiele sind Kratzer, Dellen, Risse oder Verschmutzungen auf Oberflächen. Die Erkennung erfolgt beispielsweise durch Vergleiche von Ausschnitten oder Merkmals-Speichernetze, die unbekannte Texturen bzw. Formen als anomal markieren.
Logische Anomalien: Diese Anomalien verletzen die semantischen oder räumlichen Regeln, die aus korrekten Bildern gelernt wurden, ohne dass einzelne Objekte technisch defekt wären. Beispiele sind fehlende oder zusätzliche Bauteile, falsche Platzierung, inkorrekte Anordnung oder abweichende Anzahl erwarteter Komponenten. Ihre Detektion erfordert ein Verständnis der globalen Objektbeziehungen und -zähler, etwa durch Autoencoder oder Hybridmodelle, die sowohl lokale als auch logische Constraints prüfen.
Ein robustes Anomalieerkennungssystem muss mit beiden Fehlerarten umgehen können – und darf dabei nicht auf starre Referenzbilder oder einfache Differenzen setzen. Es braucht Kontextwissen und die Fähigkeit, „Sinn“ zu interpretieren, nicht nur „Abweichung“.
Abbildung 2: Beispiel für unterschiedliche Klassen industrieller Anomalien. (a) Strukturelle Anomalie: der Draht ist beschädigt bzw. gerissen. (b) Logische Anomalie: anstelle eines einzelnen Drahts sind zwei fehlerfrei verlegte Drähte vorhanden. Während erstere lokal sichtbar wird, verletzt letztere die semantische Erwartung an die korrekte Bauteilkonfiguration.
Supervised oder Unsupervised?
Eine verbreitete Annahme: Um Anomalien zuverlässig erkennen zu können, braucht ein Modell möglichst viele Fehlerbeispiele. In der industriellen Realität ist jedoch das Gegenteil der Fall: Fehler sollen so selten wie möglich auftreten – idealerweise gar nicht. Und genau deshalb fehlen sie in der Regel fast vollständig in den verfügbaren Datensätzen.
Für klassische supervised Verfahren ist das ein erhebliches Problem. Ohne ausreichende Fehlerbeispiele können sie keine sinnvollen Trennlinien zwischen Gut und Schlecht ziehen. Stattdessen setzen moderne industrielle Anwendungen auf unsupervised oder One-Class-Learning-Verfahren, bei denen ausschließlich mit Gutbildern trainiert wird. Das Modell lernt die Charakteristik der „Normalität“ – und erkennt alles als potenziell anomal, was davon signifikant abweicht.
Diese Verfahren benötigen zwar keine expliziten Fehlerdaten, stellen aber andere Anforderungen: Die Definition dessen, was als „normal“ gilt, muss klar und konsistent sein. Zudem müssen typische produktionsbedingte Abweichungen – etwa leichte Positionsänderungen, Oberflächenschwankungen oder unterschiedliche Belichtungen – im Trainingsdatensatz ausreichend vertreten sein, damit das System sie nicht fälschlich als Fehler interpretiert.
Nur wenn die reale Varianz des Produktionsalltags im „Normalbild“ abgebildet ist, kann das System robust gegenüber echten Schwankungen agieren.
Abbildung 3: Eine vollständige Annotation aller potenziellen Produktionsfehler ist in der Praxis kaum möglich. Stattdessen kann das „Normale“ unüberwacht gelernt und anschließend Abweichungen als potenzielle Anomalien erkannt werden.
Gelabelte Daten: Der Engpass der Praxis
Selbst wenn Fehlerbilder verfügbar wären – ihre Annotation ist teuer und aufwändig. Ihre gezielte Erzeugung ist oft nicht praktikabel: Produktionslinien müssen angehalten, Fehler absichtlich provoziert und anschließend händisch behoben werden – ein aufwendiger und teurer Prozess, der sich nur selten rechtfertigt.
Hinzu kommt: Selbst in sehr großen Produktionsdatensätzen sind reale Fehler oft schlicht noch nicht aufgetreten. Das ist kein Nachweisproblem, sondern ein erwünschter Zustand – industrielle Qualitätssicherung zielt ja gerade darauf ab, Fehler frühzeitig zu vermeiden. Für das Training eines Modells bedeutet das jedoch: Es fehlen konkrete Beispiele für Anomalien, die künftig dennoch erkannt werden müssen. Das macht die existierenden gelabelten Fehlerdaten – sofern vorhanden – oft unvollständig und nicht repräsentativ für die ganze Bandbreite potenzieller Abweichungen.
Unsupervised Verfahren bieten hier einen gangbaren Weg: Sie benötigen keine expliziten Fehlerbilder, sondern lernen ausschließlich von fehlerfreien Beispielen. In vielen industriellen Szenarien sind sie daher die einzige realistische Option – vorausgesetzt, die Qualität und Konsistenz der Gutbilder ist hoch, und die Modellarchitektur erlaubt es, zwischen tolerierbarer Varianz und echten Auffälligkeiten zu unterscheiden.
Variabilität als Realität – und Herausforderung
Industrielle Bilddaten sind selten homogen. Selbst bei gleichbleibenden Prozessen unterliegen sie natürlicher Varianz – durch:
Positionsvariable Komponenten wie Anschlusskabel, Hydraulikleitungen oder Schläuche
Veränderliche Lichtverhältnisse durch Umgebungslicht, Maschinenschatten oder saisonale Einflüsse
Streuung bei Oberflächen durch Fertigungstoleranzen, Verunreinigungen oder Montagespuren
Diese Faktoren führen dazu, dass zwei „korrekte“ Bilder oft deutlich voneinander abweichen – obwohl beide fehlerfrei sind. Ein zu empfindliches System meldet hier ständig Fehlalarme. Ein zu grobes System übersieht echte Probleme. Der schmale Grat zwischen Sensitivität und Robustheit ist die zentrale Herausforderung industrieller Anomalieerkennung.
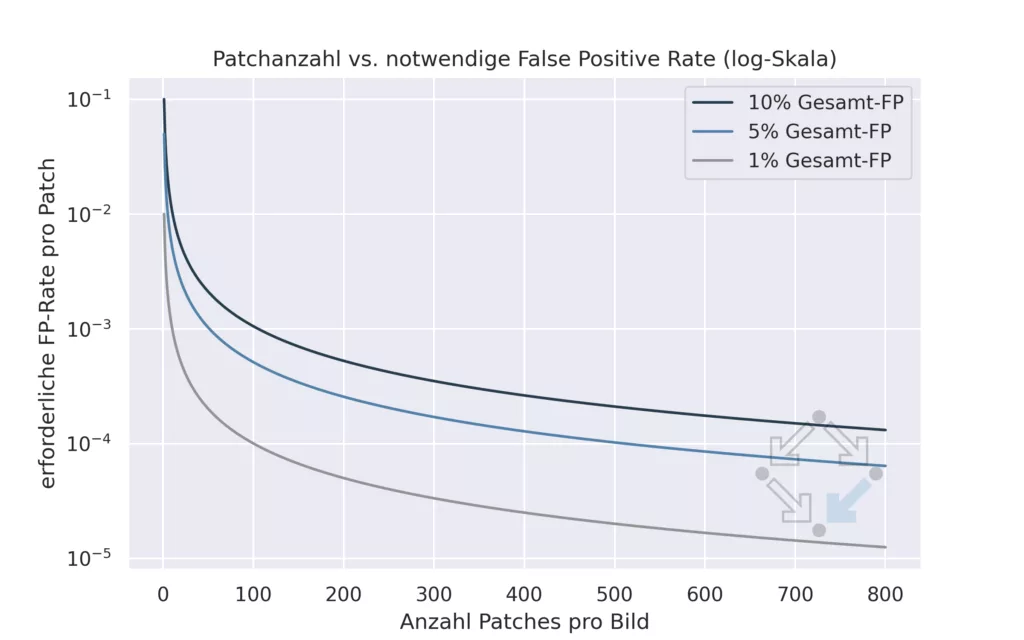
Besonders kritisch wird es bei hochaufgelösten Bildern: Da potenzielle Anomalien an beliebiger Stelle auftreten können, arbeiten viele Verfahren auf 256×256 Pixel großen Ausschnitten. Um ein detailreiches Bild von z. B. 2048×2048 px zu untersuchen, sind hunderte dieser Ausschnitte nötig.
Das Problem: Jeder Ausschnitt ist ein eigener „Test“. Und je mehr Tests durchgeführt werden, desto höher ist die Wahrscheinlichkeit für falsch-positive Ergebnisse – selbst bei guter Einzel-Performance. Dieses statistische Akkumulationsproblem ist eine oft unterschätzte Quelle für Fehler und Frustration in der Praxis.
Abbildung 4: Patchbasierte Anomalieerkennung erfordert eine extrem zuverlässige Erkennung einzelner Fehler. Bei 500 Patches pro Bild darf die Fehlklassifikationsrate pro Patch höchstens 1 zu 10.000 betragen, um eine False-Positive-Rate von 5 % pro Bild nicht zu überschreiten.
Adaptivität als Schlüssel zur Zukunft
Selbst ein gut trainiertes, fein justiertes System verliert seine Wirksamkeit, wenn sich die Realität verändert. Neue Zulieferer, geänderte Bauteile, Updates am Produktdesign – sie alle verändern die visuelle Erscheinung des Normalzustands.
Ein System, das darauf nicht reagieren kann, wird entweder alles als Fehler melden – oder gar nichts mehr. Moderne Anomalieerkennung muss daher lernfähig und adaptiv sein. Ziel ist es, mit wenigen Beispieldaten neue „Normalzustände“ zu integrieren, ohne das Modell komplett neu trainieren zu müssen. Verfahren aus dem Bereich des Few-Shot Learning oder Continual Learning werden hier zunehmend relevant.
Hardwareanforderungen im Echtbetrieb
Ein Aspekt, der oft unterschätzt wird, sind die technischen Anforderungen, die ein Anomalieerkennungssystem im Livebetrieb stellt.
Zwar gelten viele moderne Computer-Vision-Modelle in der Inferenz als vergleichsweise effizient – in der Praxis sind dennoch spezialisierte Hardware-Ressourcen erforderlich, um zuverlässig und in Echtzeit zu arbeiten.
Starke CPUs sind notwendig für Bildvorverarbeitung: Zuschnitt, Farbraumkonvertierung, Kontrastanpassung und weitere Verarbeitungsschritte müssen bei jedem Bild durchgeführt werden – oft unter Zeitdruck und parallel zur laufenden Linie.
Grafikkarten (GPUs) bieten bei der eigentlichen Bildauswertung (also dem KI-Inferenzschritt) den entscheidenden Geschwindigkeitsvorteil – besonders bei hochaufgelösten Bildern oder komplexen Modellen.
Ob die Hardware direkt an der Linie (z. B. in einem Edge-Gerät) installiert oder zentral betrieben wird (z. B. mit Kameraanbindung an einen Rechenserver), hängt vom jeweiligen Szenario ab. Wichtig ist: Diese Anforderungen sollten bereits in der Planungsphase berücksichtigt werden.
Nur so lässt sich vermeiden, dass ein funktionierender Prototyp später an zu langen Antwortzeiten oder Systemüberlastung scheitert.
RISC Software als Lösungspartner: Von der Modellarchitektur zur operativen Umsetzung
Die Umsetzung industrieller Anomalieerkennung erfordert mehr als das bloße Anwenden vorgefertigter Modelle. Jedes Einsatzszenario bringt eigene Anforderungen mit: unterschiedliche Bildqualitäten, Produktvarianten, Taktzeiten oder Integrationsumgebungen. Standardmodelle stoßen hier oft an Grenzen – sei es in der Robustheit, in der Skalierbarkeit oder im Umgang mit variabler Realität.
Die RISC Software GmbH versteht sich als Lösungspartner, der diese Komplexität nicht scheut: Wir analysieren den konkreten Anwendungsfall, passen vorhandene Modellarchitekturen gezielt an – und integrieren sie in funktionierende Systeme. Von der Bildaufnahme bis zur produktionsnahen Entscheidung unterstützen wir Unternehmen dabei, KI-basierte Qualitätskontrolle nicht nur zu testen, sondern nachhaltig und produktiv zu machen.
Fazit
Anomalieerkennung ist kein fertiges Produkt, sondern ein kontinuierlicher Prozess. Wer die Realität industrieller Bilddaten ernst nimmt – mit ihrer Varianz, Unausgewogenheit und permanenten Veränderung – kann KI-basierte Qualitätskontrolle sinnvoll und wirksam einsetzen. Voraussetzung sind passende Modelle, realistische Erwartungen und ein agiles Konzept für Betrieb und Weiterentwicklung.
Sechs Fragen, die sich Unternehmen vor dem Einsatz von Anomalieerkennung stellen sollten
1
Werden Bilder in gleichbleibender Qualität erzeugt?
Anomalieerkennung lebt von Konsistenz. Unterschiede bei Kameraposition, Beleuchtung oder Hintergrund führen schnell zu Fehlalarmen. Nur wenn die Bildaufnahme technisch stabil und wiederholbar ist, kann KI sinnvoll eingesetzt werden.
2
Gibt es genug Beispielbilder für den Normalzustand?
Auch wenn keine Fehlerdaten vorhanden sind: Ein gutes Anomalieerkennungsmodell braucht viele Bilder von fehlerfreien Produkten. Je größer und vielfältiger dieses Set, desto robuster kann das System später reagieren.
3
Sind bekannte Fehlerarten dokumentiert – auch mit Bildbeispielen?
Fehlerbilder mögen beim Training teilweise nicht nötig sein, sind aber essentiell bei der Bewertung des fertigen Systems. Nur wenn klar ist, welche Anomalien erkannt werden sollen, lässt sich die Leistungsfähigkeit objektiv beurteilen.
4
Wie oft ändern sich Bauteile, Lieferanten oder Produktvarianten?
Ein KI-System erkennt, was es kennt. Wenn sich das Aussehen von Bauteilen regelmäßig ändert, braucht das System die Fähigkeit zur schnellen Anpassung – und das Projekt muss so konzipiert sein, dass solche Anpassungen eingeplant sind.
5
Wer kann im Unternehmen beurteilen, ob ein gemeldeter Fehler tatsächlich einer ist?
Kein System ist perfekt. Es wird Grenzfälle geben. Wichtig ist, dass intern eine Ansprechperson (z. B. aus der Qualitätssicherung) definiert ist, die Rückmeldungen geben kann – damit das System laufend besser wird.
6
Gibt es geeignete Hardware für den Live-Betrieb?
Für Tests reicht oft der Laptop – für den produktiven Einsatz braucht es zuverlässige Bildverarbeitung in Echtzeit. Das erfordert leistungsfähige CPU-Ressourcen und meist auch eine GPU – direkt an der Linie oder im Netzwerk.