



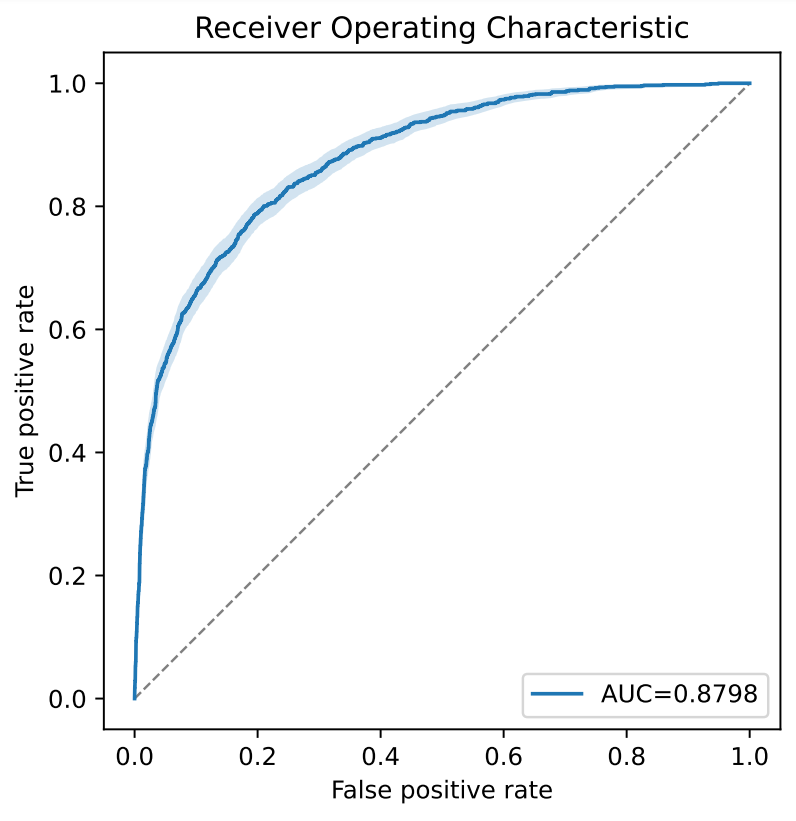
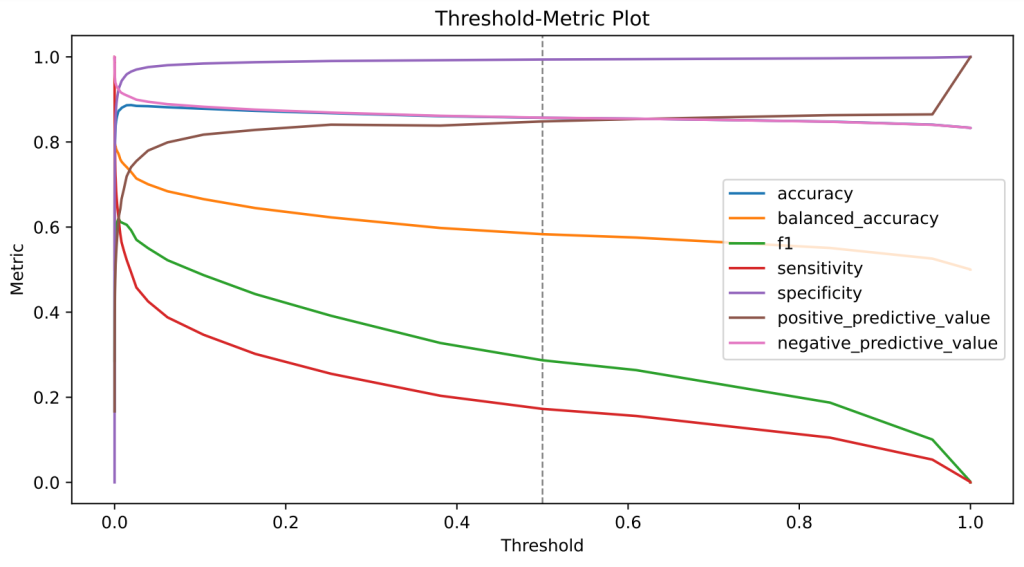
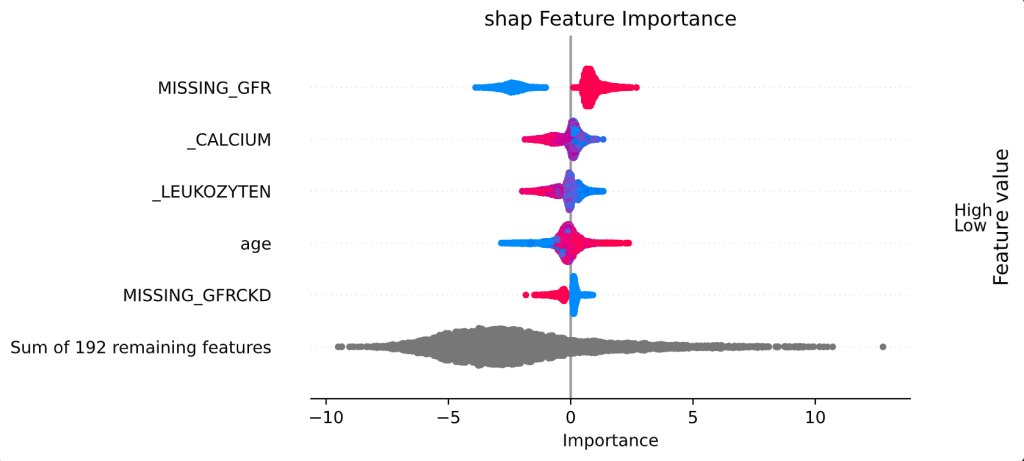








Explainable Artificial Intelligence (XAI): Wie Machine-Learning-Vorhersagen interpretierbar(er) werden
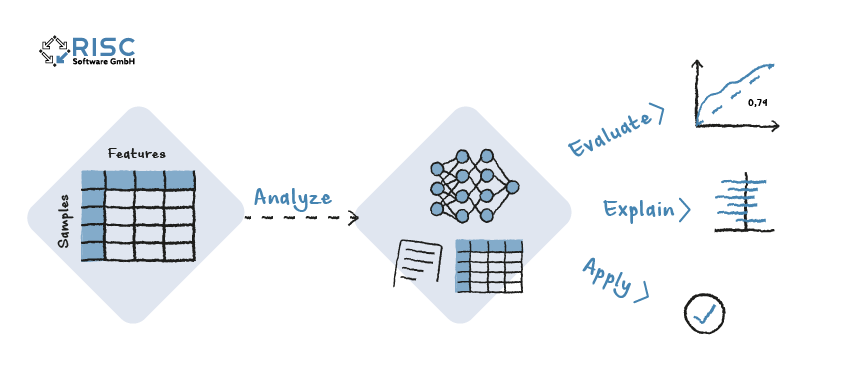
Künstliche Intelligenz ist auf künstliche neuronale Netzwerke zurückzuführen, die dem menschlichen Gehirn nachempfunden sind. In bestimmten Situationen ist es notwendig, die Entscheidungsgrundlage der Modelle aus dem Bereich Deep-Learning für Vorhersagen erklären zu können.
mehr erfahren