



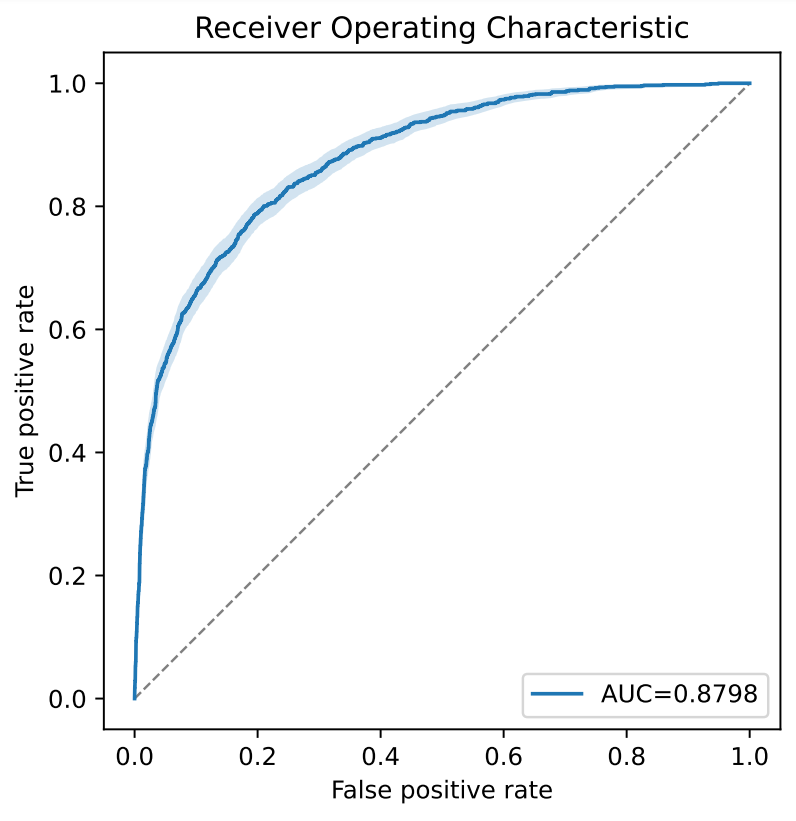
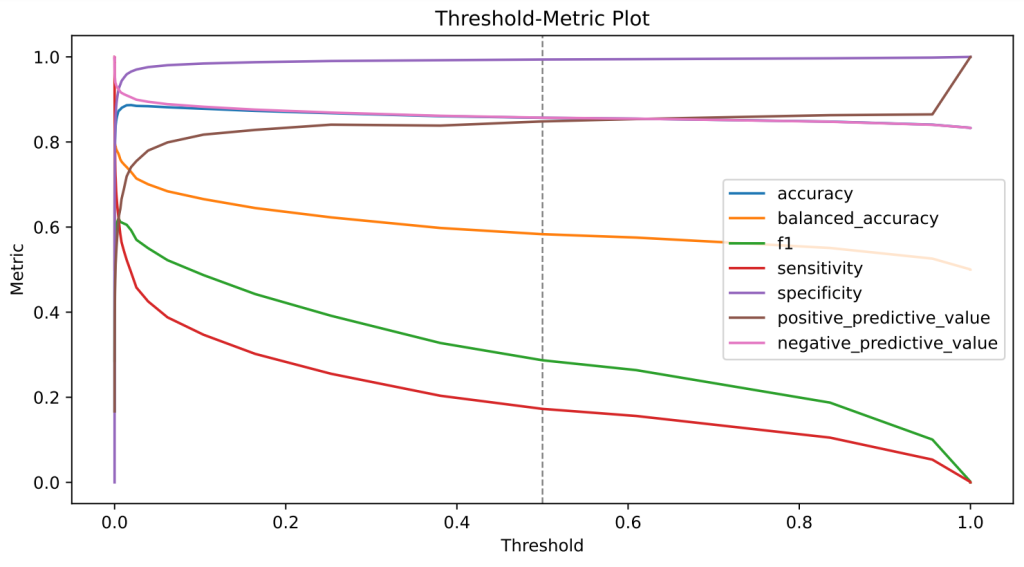
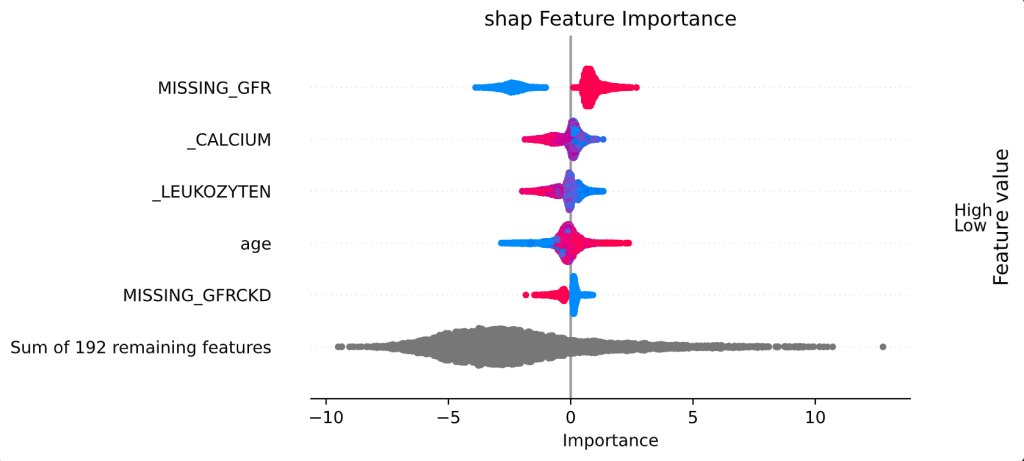








Explainable Artificial Intelligence (XAI): How Machine Learning Predictions Become Interpretable
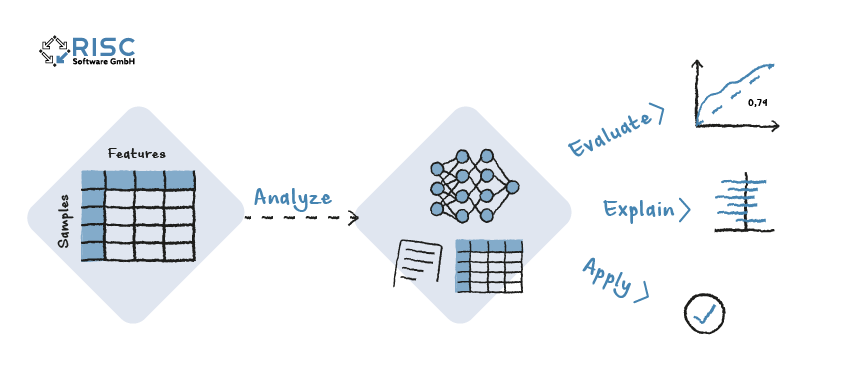
Artificial intelligence is due to artificial neural networks that are modeled on the human brain. In certain situations, it is necessary to be able to explain the decision-making basis of the models from the field of deep learning for predictions.
mehr erfahren