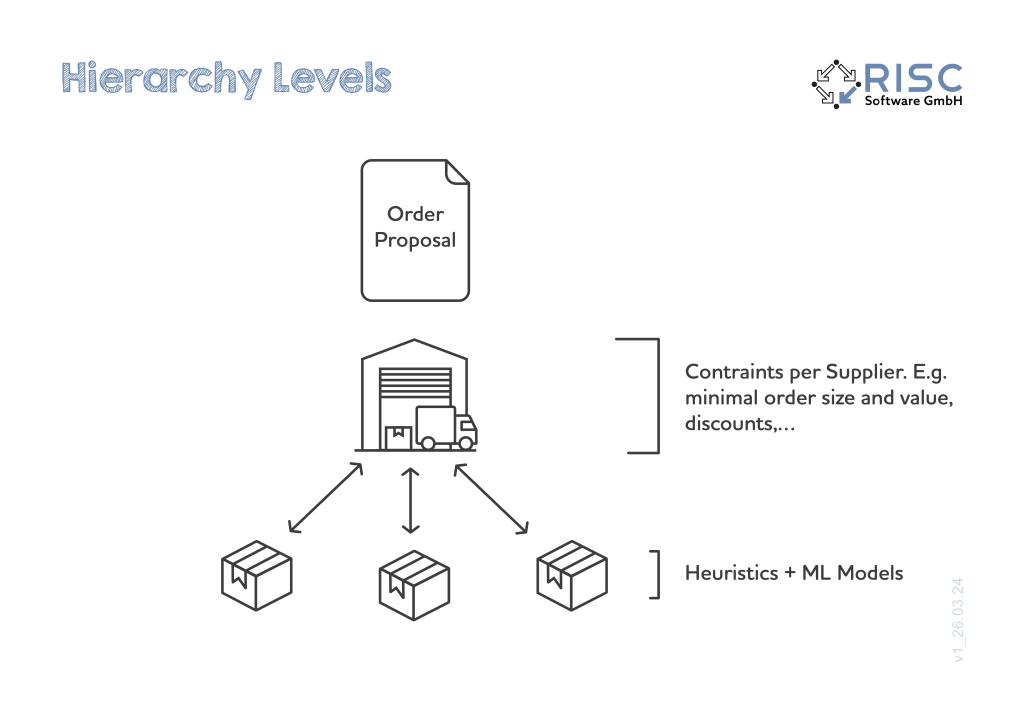
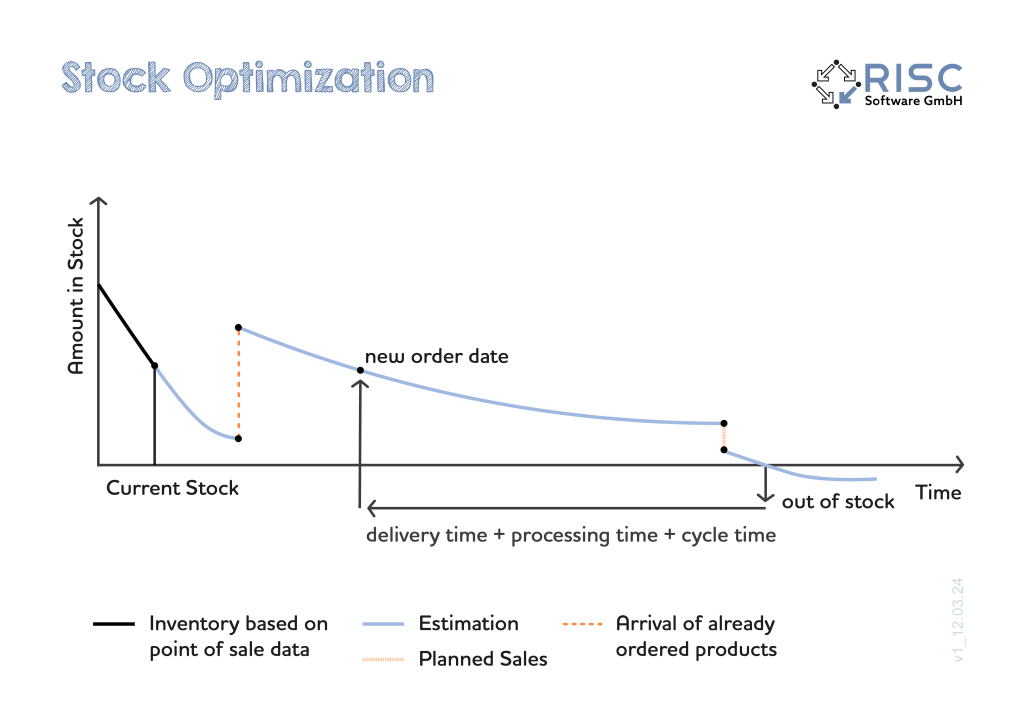
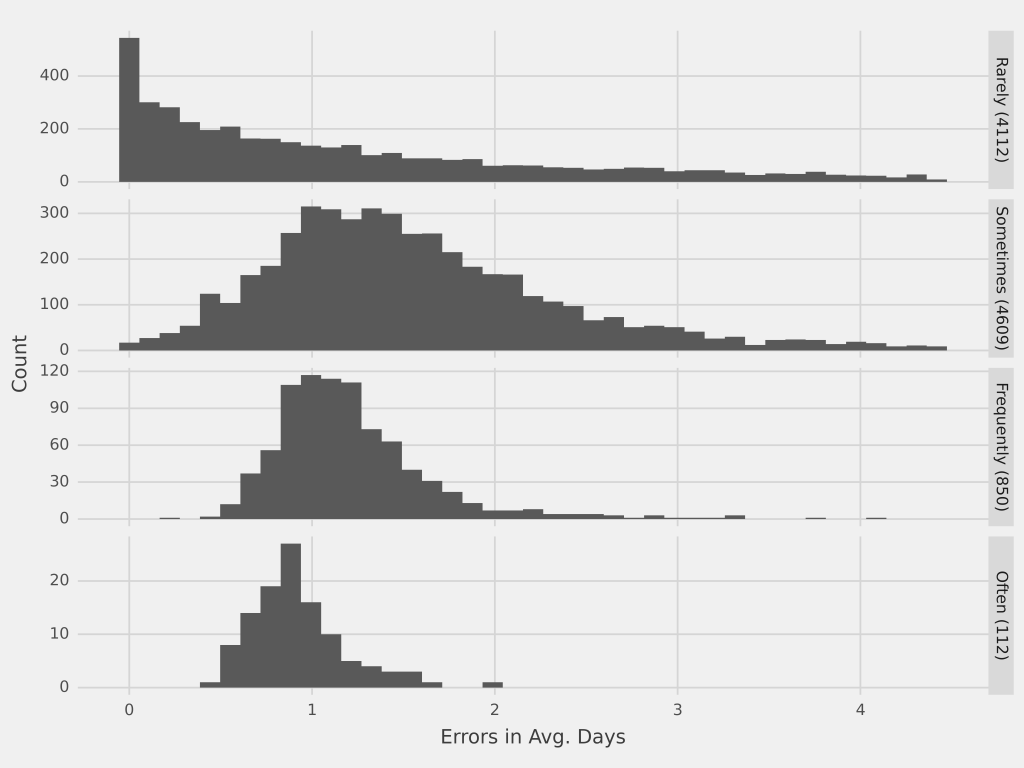
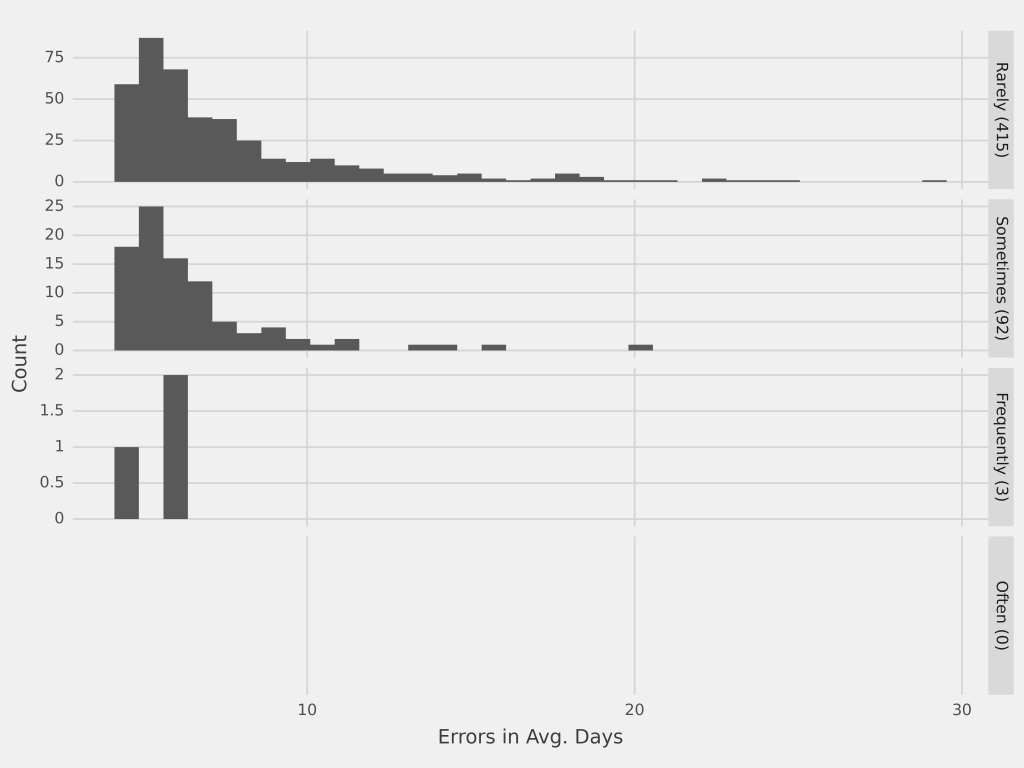
Referenzen
[1] J. Aastrup, H. Kotzab, Forty years of out-of-stock research – and shelves are still empty, The International Review of Retail, Distribution and Consumer Research 20 (2010) 147–164. URL: https://doi.org/10.1080%2F09593960903498284. doi:10.1080/ 09593960903498284.
[2] K. Q. Dadzie, E. Winston, Consumer response to stock-out in the online supply chain, International Journal of Physical Distribution & Logistics Management 37 (2007) 19–42. doi:10.1108/09600030710723309.
[3] S. Anand, S. Chadha, Out-of-stocks are more costly than losing a sale — but there’s a fix, https://www.supplychaindive.com/news/ reduce-retail-out-of-stock-AT-Kearney/545439/, 2019. Accessed: 2023-03-29.
[4] W. Zinn, P. C. Liu, CONSUMER RESPONSE TO RETAIL STOCKOUTS, Journal of Business Logistics 22 (2001) 49–71.doi:10.1002/j.2158-1592.2001.tb00159.x.
[5] G. Ke, Q. Meng, T. Finley, T. Wang, W. Chen, W. Ma, Q. Ye, T.-Y. Liu, Lightgbm: A highly efficient gradient boosting decision tree, in: Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, Curran Associates Inc., Red Hook, NY, USA, 2017, p. 3149–3157.
[6] S. Makridakis, E. Spiliotis, V. Assimakopoulos, M5 accuracy competition: Results, findings, and conclusions, International Journal of Forecasting 38 (2022) 1346–1364. doi:10.1016/j.ijforecast.11.013.
[7] P.Kannisto,D.Ha ̈stbacka,T.Gutie ́rrez,O.Suominen,M.Vilkko,P.Craamer, Plant-wide interoperability and decoupled, data-driven process control with message bus communication, Journal of Industrial Information Integration 26 (2022) 100253. doi:10.1016/j.jii.2021.100253.
[8] Falkner, D., Bögl, M., Gattinger, A., Stainko, R., Zenisek, J., & Affenzeller, M. (2024). Integrating machine learning into supply chain management: Challenges and opportunities. Procedia Computer Science, 232, 1779–1788. doi:10.1016/j.procs.2024.01.176