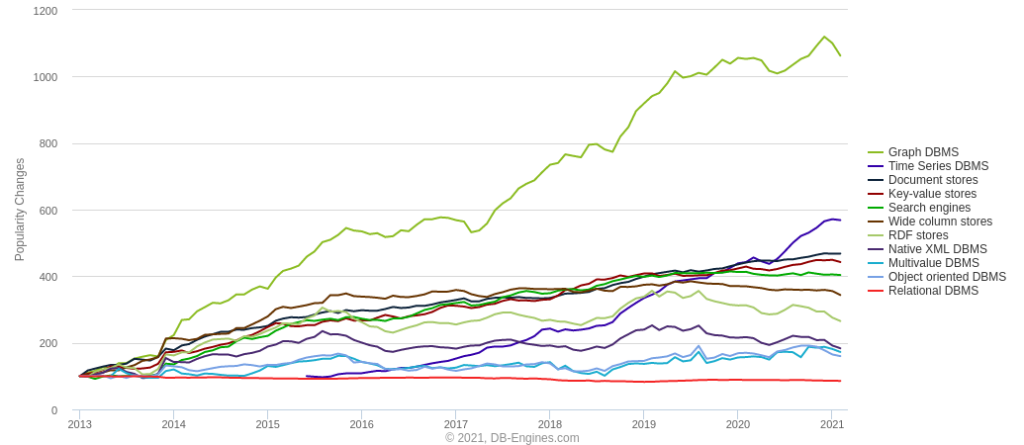











Graphdatenbanken in der Praxis
Graphdatenbanken ermöglichen eine intuitive Abbildung vieler Real-World-Szenarien wie industrielle Fertigung, Verkehrsdatenanalyse oder der IT-Infrastrukturüberwachung. Zusätzlich ermöglichen sie, dass sich auch die Abfragen eng an die modellierte Realität anlehnen.
mehr erfahren