

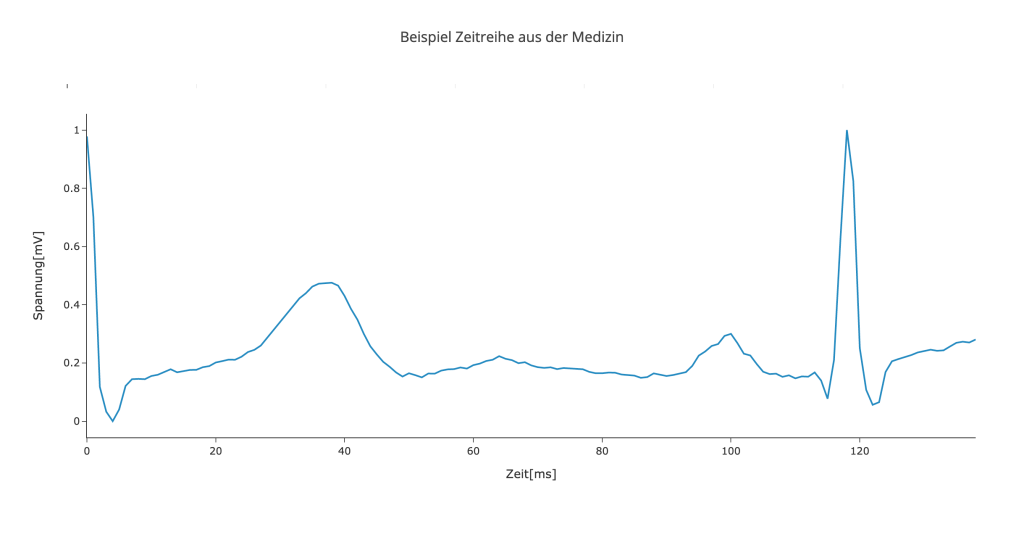
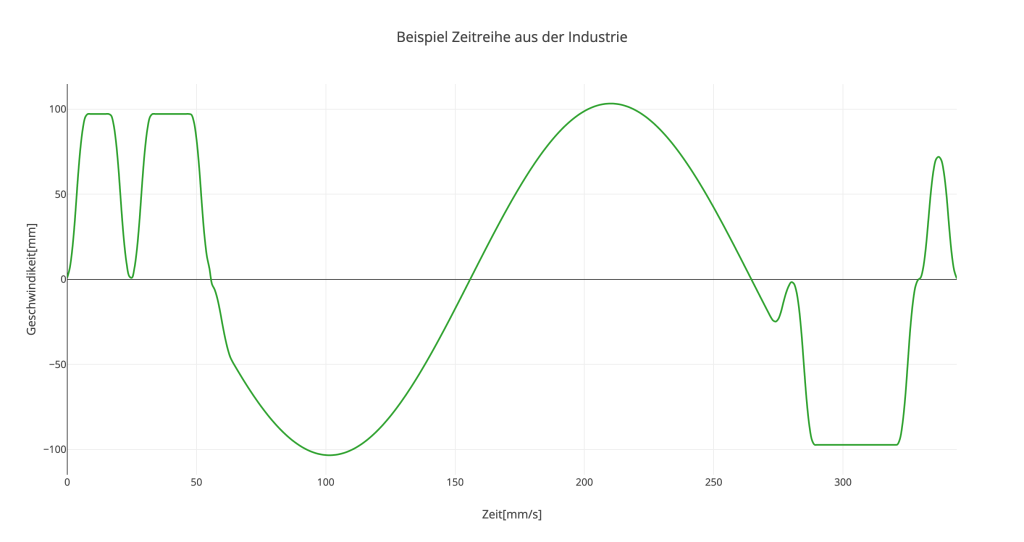
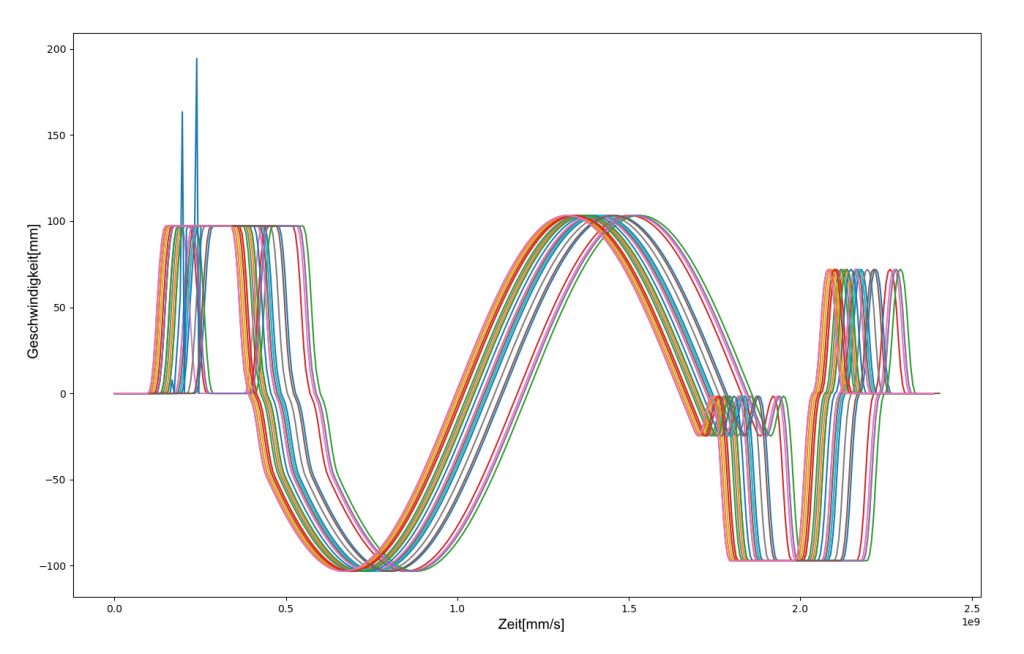



Vertrauen in die Künstliche Intelligenz
Wenn wir KI-Systeme erschaffen und verwenden, müssen wir uns in Zukunft nicht nur über die Chancen, sondern auch über die Risiken und die Herausforderungen bei deren Einsatz bewusst sein. Guidelines können uns dabei helfen, KI-Systeme zu erschaffen, die nicht nur effizient, sondern auch ethisch korrekt, sicher und vertrauenswürdig sind.
mehr erfahren

