(R)Evolution der Sprachmodelle – ChatGPT
Antworten auf die wichtigsten Fragen zu den Künstlichen Intelligenzen ChatGPT, Bard und co.
von Sandra Wartner, MSc
In den letzten Wochen drehte sich alles um die neuen Künstlichen Intelligenzen (KIs) der großen Player. Seit der Veröffentlichung von OpenAIs Chatbot-Revolution ChatGPT Ende November 2022 (vgl. Seite von OpenAI) befindet sich das Sprachmodell in einer für jeden zugänglichen Forschungs- bzw. Feedbackphase und hat damit das öffentliche Interesse geweckt. Mit bereits über 100 Mio. User*innen im Jänner zeigten sich die vielseitigen Funktionen und Anwendungsszenarien, welche die KI zu bieten hat. Sie hilft bei alltäglichen und beruflichen Schreibaufgaben wie Einkaufslisten oder kreativen Marketingtexten, liefert Vorschläge zur Planung von Geburtstagspartys, schreibt Gedichte und Songtexte oder hilft bei Programmieraufgaben.
Als Antwort auf die Veröffentlichung von ChatGPT kündigte Anfang Februar auch Google die eigene Lösung Bard an. Auch China will als weiterer Konkurrent mitmischen und plant mit Ernie von Baidu im März ein Ende der Testphase. Wie sich die Sprachmodelle in unseren Alltag einfügen und uns unterstützen werden, ist noch nicht ganz klar. Dass ein Umdenken erforderlich ist und sich auch die Berufswelt dementsprechend anpassen wird, lässt sich ebenfalls nicht abstreiten.
Doch was steckt eigentlich hinter der Technologie rund um die neuen Künstlichen Intelligenzen?
Inhalt
- Ein weiterer Meilenstein für die KI-Landschaft
- Wie kann ich ChatGPT selbst ausprobieren?
- Wie zuverlässig sind die Antworten der Modelle und wo liegen ihre Grenzen?
- Welches Potenzial für Geschäftsanwendungen verbirgt sich hinter den Technologien?
- Autorin
Dieser Fachbeitrag bezieht sich auf einen Wissensstand vom 22.03.2023. Spätere Änderungen oder Neuerungen sind nicht berücksichtigt.
Ein weiterer Meilenstein für die KI-Landschaft
Die dahinterliegende Technologie ist Natural Language Processing, kurz NLP (vgl. einen unserer Fachbeiträge zu NLP) und ermöglicht es Maschinen, menschliche Sprache zu verarbeiten und das Wissen in Form von (Sprach-)Modellen abzubilden. Einen wesentlichen Meilenstein dazu lieferte die Veröffentlichung der Transformer-Architektur (siehe auch [1], bzw. einen weiteren Fachbeitrag) im Jahr 2017, vorangetrieben durch die Fortschritte im Bereich des Deep Learning, der Verfügbarkeit großer Mengen an Trainingsdaten sowie der gestiegenen Rechenleistung. Um Sprachrepräsentationen zu lernen, werden dem Sprachmodell in der Pre-Trainingsphase riesige Mengen an Textdaten zur Verfügung gestellt. Zu diesem Zeitpunkt hat das Modell noch keine Informationen zu konkreten Aufgaben wie bspw. Texte übersetzen oder Informationen auswerten, und muss diese in der nachfolgenden Finetuning-Phase mit Hilfe eines annotierten Datensets erlernen.

Das Nachahmen natürlicher Konversationen in Form von konversationeller KI (conversational AI) konnten wir über virtuelle Assistent*innen wie bspw. Siri und Alexa bereits in den letzten Jahren miterleben, die neue Generation schafft es allerdings noch besser, menschliche Interaktionen zu simulieren. Wer in den letzten Jahren die Medien aufmerksam mitverfolgt hat, wird bereits immer wieder über News zu den ChatGPT-Vorgängermodellen GPT-2 (2019) und GPT-3 (2020) gestolpert sein. GPT ist ein Akronym für Generative Pretrained Transformer, und nutzt – wie der Name bereits verrät – die oben genannte Transformer-Architektur, um basierend auf einer textuellen Konversationsaufforderung einen zum Kontext und Thema passenden, menschenähnlichen Text als Antwort zu generieren. Die Modelle wurden von OpenAI, einem US-amerikanischen Unternehmen zur Erforschung von Künstlicher Intelligenz, entwickelt und zählen zu den bisher größten neuronalen Netzwerken.
Chat-GPT gehört als finegetunte Version von GPT-3 zur Familie GPT-3.5 und mit 175 Milliarden Parameter zu einem der leistungsstärksten State-of-the-Art Sprachmodelle. Trainiert wurde dieses auf einer riesigen Menge unterschiedlicher Textdaten aus Websites, Artikeln und Büchern, um Aufgaben zu erledigen wie bspw. Texte verfassen, analysieren und zusammenfassen bzw. umschreiben, aber auch zum Schreiben und Analysieren von Programmcode in unterschiedlichen Programmiersprachen. Am besten funktioniert ChatGPT in Englisch, kann aber auch andere Sprachen verarbeiten. Microsoft hat als einer der wichtigsten Geldgeber für die Integration der Technologie in der Suchmaschine Bing eine weitere Milliardeninvestition getätigt (siehe auch Blogbeitrag von Microsoft), und es kann gut sein, dass manche Funktionen zukünftig auch in Outlook oder Word anzutreffen sein werden. Die Nutzung des Bing-Chatbots wurde zu Beginn der Startphase erstmals eingeschränkt, nachdem das Modell unangemessenes Verhalten (u.a. Liebeserklärungen, Drohungen) gezeigt hat.
Auch Google hat inzwischen seinen eigenen Chatbot Bard angekündigt (siehe auch Blogbeitrag von Google). Dieser basiert auf dem Google Sprachmodell LaMDA (Language Model for Dialogue Applications), welches hauptsächlich auf Texten und Dialogen trainiert wurde. Einer der größten Unterschiede liegt aktuell darin, dass Bard – im Gegensatz zu ChatGPT’s Wissenslimit bis zum Jahr 2021 – Informationen aus dem Web bezieht. Bard befindet sich aktuell ebenfalls noch in der Testphase, jedoch nur für eine ausgewählte Testgruppe.
Wie kann ich ChatGPT selbst ausprobieren?
Um das Können von ChatGPT selbst zu testen, wird ein OpenAI-Account benötigt [Link zu ChatGPT]. Über ein Dialogfenster im Browser entsteht eine Art Chat mit dem Modell, wobei man das Verfassen der Antworten in Echtzeit mitverfolgen kann.
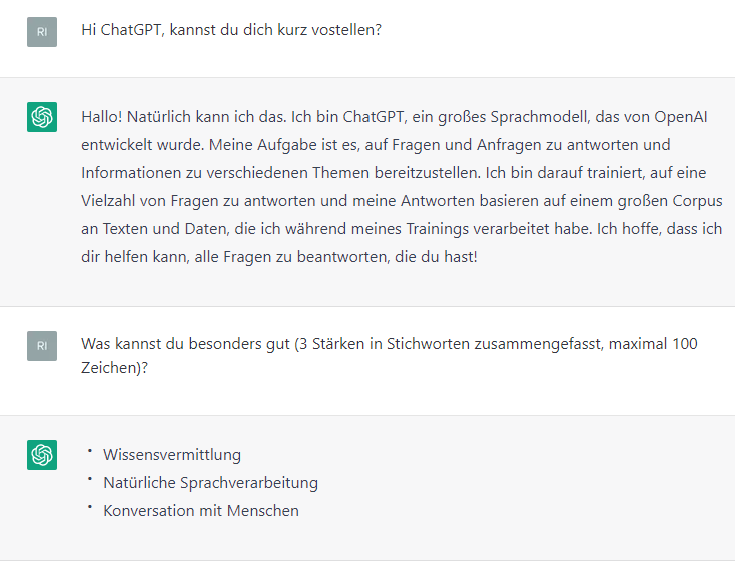
Wer neugierig ist, muss sich eventuell etwas gedulden, da es aufgrund der großen Nachfrage immer wieder zu Stabilitäts- und Kapazitätsproblemen kommt. Die Nutzung von ChatGPT ist in der aktuellen Entwicklungsphase kostenlos, es gibt allerdings schon erste Kostenmodelle wie ChatGPT Plus (Link zu ChatGPT Plus), die auch zu Spitzenzeiten einen stabilen Zugriff auf das Modell ermöglichen sollen. Da die eingegebene Daten u.a. zur weiteren Verbesserung bzw. Evaluierung des Modells ausgewertet werden, ist es wichtig, keine sensiblen und persönlichen Daten einzugeben.
Wie zuverlässig sind die Antworten der Modelle und wo liegen ihre Grenzen?
ChatGPT liefert auf den ersten Blick eine beeindruckende Performance. Die Konversation wirkt so (erschreckend) natürlich, als würde man mit einer menschlichen Person chatten. Die Fähigkeiten haben aber auch gewisse Grenzen [siehe Beschreibung von OpenAI].
Kein übereilter Vertrauensvorschuss
Auch wenn die Modellantworten sehr plausibel klingen, sind diese nicht immer korrekt. ChatGPT neigt dazu, Unwissen zu verschleiern, indem es immer eine Antwort generiert, und rät bei mehrdeutigen Anfragen welche Absicht dahintersteckt. Teilweise frei von ChatGPT erfundene Fakten oder Quellen (Fake News) und die Urheberschaft der Antworten lassen sich äußerst schwer überprüfen. Daher ist es immer notwendig, die Glaubwürdigkeit der zurückgelieferten Informationen kritisch zu hinterfragen und z.B. mit zusätzlichen Recherchen auf Korrektheit zu überprüfen.
Nichts dem Zufall überlassen?
Auch die Formulierung der Eingabe hat einen wesentlichen Einfluss auf die Antwort, die das Modell gibt. Es kann also passieren, dass ChatGPT bei einer bestimmten Frage die Antwort nicht (zufriedenstellend) beantworten kann, bei einer Umformulierung jedoch passend antwortet.
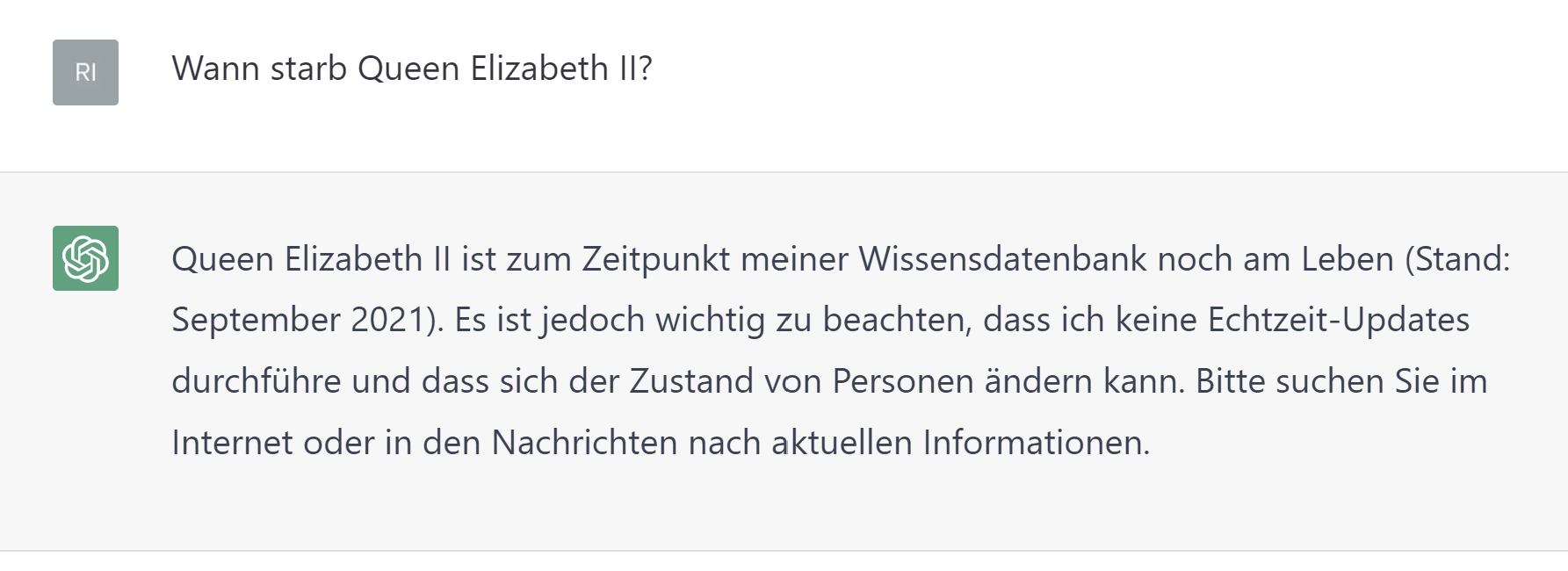
Nicht am Puls der Zeit
Da kein Zugang zu Echtzeitdaten vorliegt und die Trainingsdaten nur bis 2021 reichen, gibt es keine Garantie auf die Aktualität der gelieferten Informationen.
Verantwortungsvoller Umgang mit KI-Systemen
Da es bei den notwendigen Massen an Trainingsdaten nicht möglich ist, jeden einzelnen Text zu überprüfen, kann ein Sprachmodell u.a. gesellschaftliche oder historische Vorurteile und Stereotypen mitlernen, reproduzieren und damit zahlreiche ethische Probleme hervorrufen. Dieses Problem zeigte sich bereits 2016 bei Tay, einem Chatbot von Microsoft, welcher nach weniger als 24h wieder offline genommen werden musste, da sich dieser in einen rassistischen und sexistischen Chatbot verwandelt hatte (siehe auch Blogbeitrag von The Verge). Das vorsorgliche Treffen von Sicherheitsmaßnahmen beim Einsatz (und soweit möglich auch beim Training) dieser Modelle ist daher unbedingt erforderlich. Auch bei ChatGPT wurden Mechanismen eingebaut, um unangemessene Anfragen in der Regel nicht zu beantworten.
Wer KI-Modelle verwendet, sollte auch ein Verständnis dafür haben, wie das Modell zu dieser Antwort gekommen ist, um es verantwortungsvoll einsetzen zu können (siehe auch Fachbeitrag zu Explainable AI und Vertrauen in KI). OpenAI ist sich dieser Thematik durchaus bewusst und versucht, mehr Transparenz hinsichtlich ihrer Absichten und Fortschritte zu schaffen sowie den Finetuning-Prozess verständlicher und kontrollierbarer zu gestalten [vgl. Blogbeitrag von OpenAI].
Welches Potenzial für Geschäftsanwendungen verbirgt sich hinter den Technologien?
Die aktuellsten Errungenschaften in der Weiterentwicklung der NLP-Technologien öffnen neue Türen und prägen die Zukunft von Künstlicher Intelligenz und ihrer Anwendungen. Um die Technologien verantwortungsvoll und nutzbringend einsetzen zu können, müssen Anpassungen für neue Bereiche und die individuellen Bedürfnisse der einzelnen Branchen vorgenommen werden. Wir, die RISC Software GmbH, beschäftigen uns konkret mit dem nachhaltigen Einsatz von NLP-Technologien in praktischen Anwendungen (siehe auch Fachbeitrag zu Natural Language Understanding) und schaffen individuelle Lösungen für unsere Kund*innen. Die entwickelten KI-Systeme unterstützen und ergänzen dabei die Fähigkeiten der Domänen-Expert*innen bei der Ausführung ihrer anspruchsvollen Tätigkeiten.

Transformer-Modelle sind auch in unseren Projekten seit einigen Jahren fester Bestandteil und häufig Teil einer erfolgreichen Problemlösung in den NLP-Projekten. Mit diesen positiven Erfahrungen möchten wir den nächsten Technologie-Schritt mitgehen und die Anwendungsmöglichkeiten und Grenzen der neuen Technologien ausloten.
In den letzten Jahren sind wir immer wieder auf ähnliche Herausforderungen gestoßen. Häufig sind keine oder nicht ausreichend Trainingsdaten vorhanden, die mit hohem personellen Aufwand manuell erstellt und annotiert werden müssen, um Modelle speziell auf eine Aufgabenstellung trainieren zu können (wenn nicht glücklicherweise öffentliche Datensätze vorhanden sind, welche die Datenlage zufällig ausreichend gut abbilden). Zwar wird dieser Schritt kaum jemals völlig automatisiert durchgeführt werden können, allerdings könnten die neuen Modelle zum Vorannotieren genutzt werden und durch Menschen als Supervisor in einem weit weniger aufwändigen Prozess korrigiert und ergänzt oder für ein schnelles Prototyping genutzt werden. Auch in NLP-Tasks wie bspw. Informationsextraktion könnten Modelle wie ChatGPT (mit einem gewissen Postprocessing- und Integrations-Aufwand) als weitere Komponente eines Modell-Ensembles genutzt werden.
Sprachmodelle wie ChatGPT sind bislang noch nicht ausgereift, und dessen Einsatz muss u.a. hinsichtlich Datenschutz, Kosten-/Nutzen-Faktor, API-Abhängigkeiten sowie Erklärbarkeit und Transparenz gut überdacht und für den individuellen Anwendungsfall entschieden werden.
Es gibt derzeit viele Organisationen und Unternehmen, die mit konkreten Ideen zur Prozessverbesserung oder weiteren Optimierung ihrer Produkte durch NLP-Assistenten an uns herantreten. Die RISC Software GmbH unterstützt und begleitet ihre Kund*innen dabei gerne von der Idee bis hin zur Integration [vgl. mehr zu unseren Kompetenzen im Bereich NLP].
Kontakt
Autorin

Sandra Wartner, MSc
Data Scientist
Referenzen
[1] Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).