

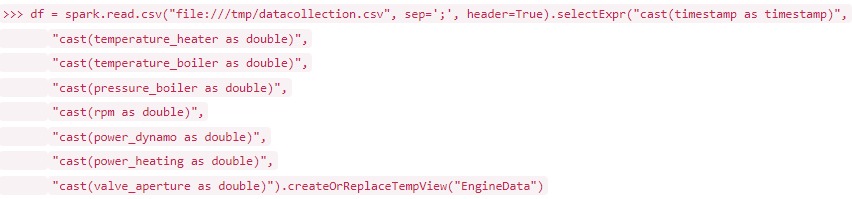






Datenversteher: Durch intelligente Graphdatenbanken Unternehmensdaten nutzen
Graphdatenbanken ermöglichen eine intuitive Abbildung vieler Real-World-Szenarien wie industrielle Fertigung, Verkehrsdatenanalyse oder der IT-Infrastrukturüberwachung. So werden Daten nicht nur effizienter gespeichert, sondern auch viel besser nutzbar.
mehr erfahren
