







Data Understanders: Leveraging enterprise data through intelligent Graph Databases
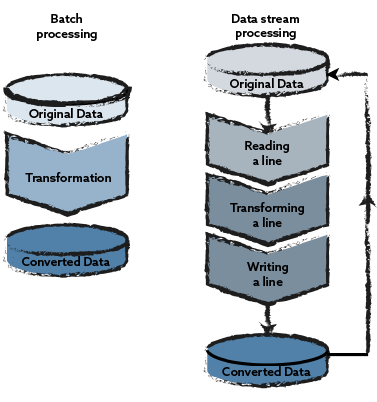
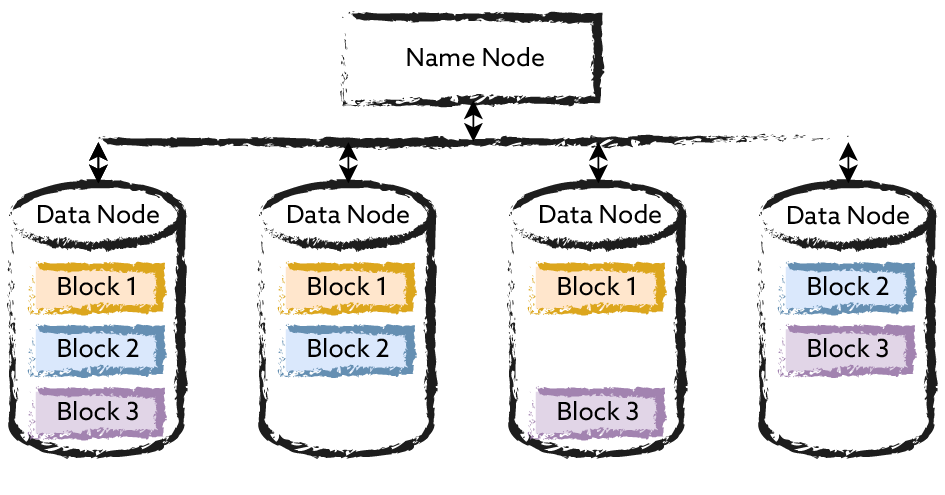
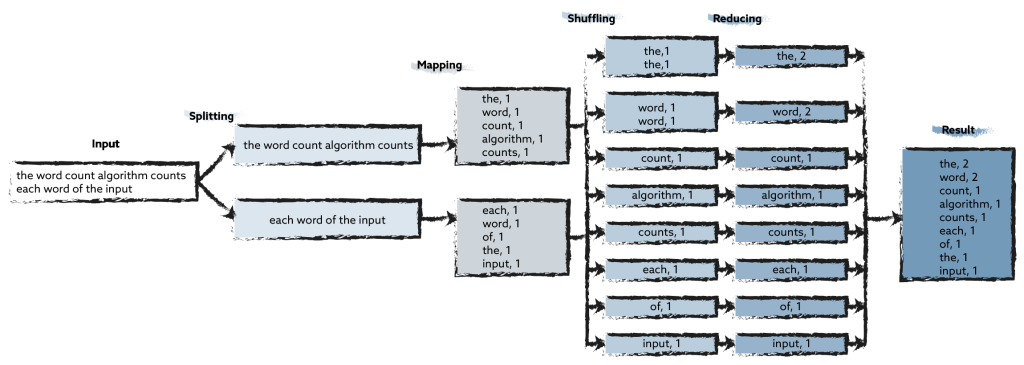
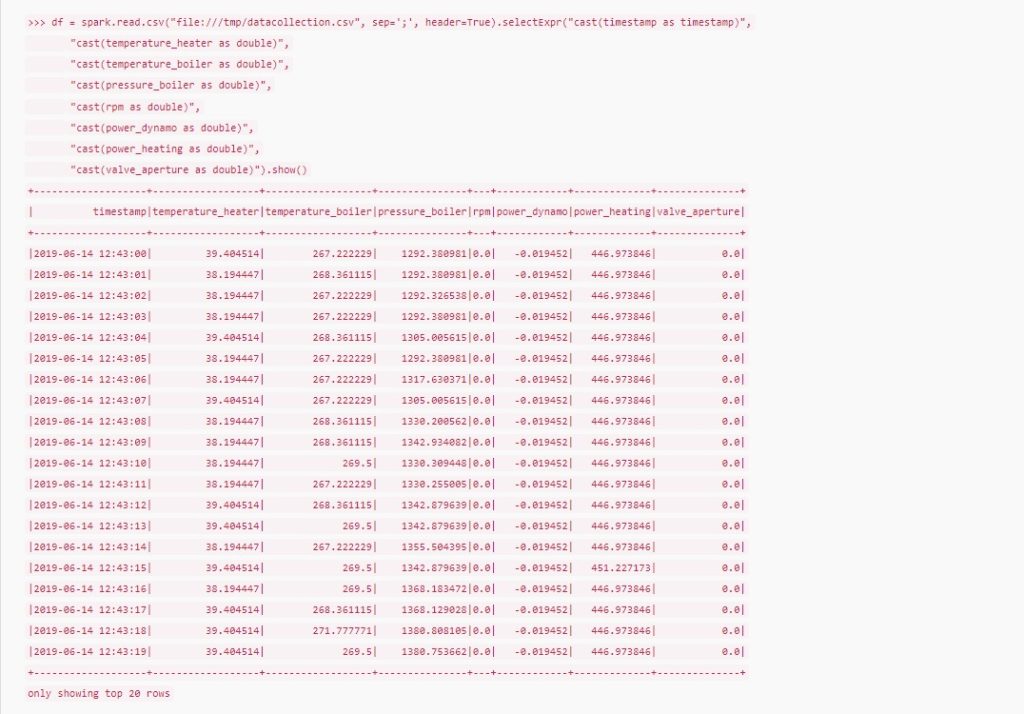
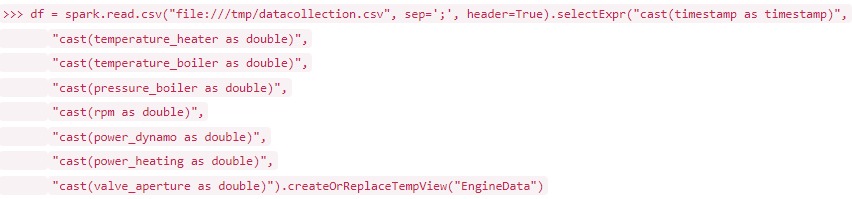
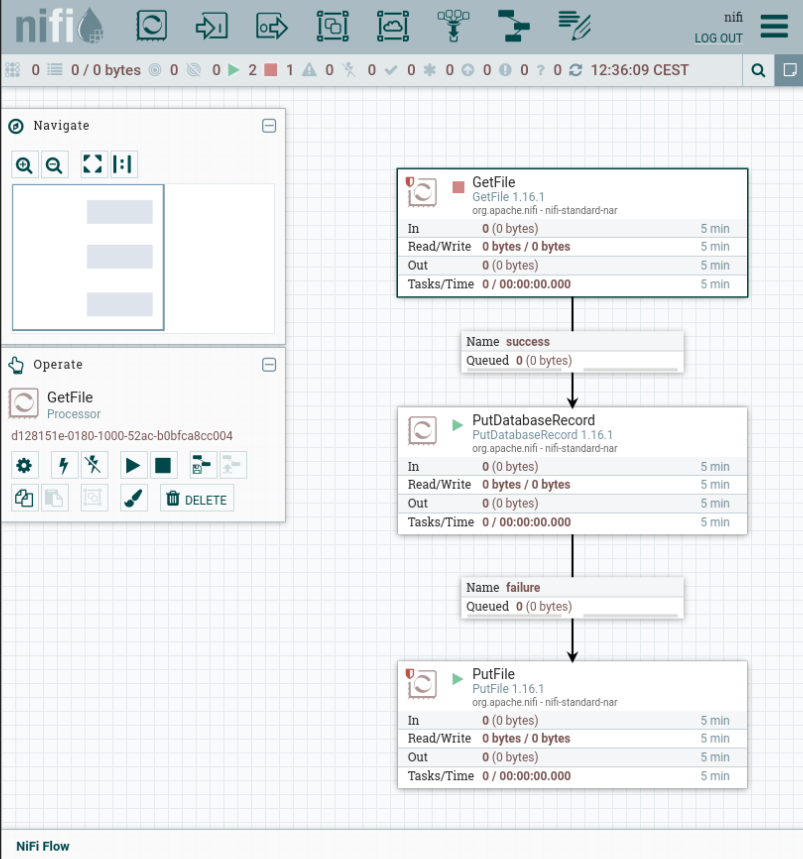
Graph databases enable intuitive mapping of many real-world scenarios such as industrial manufacturing, traffic data analysis or IT infrastructure monitoring. This makes data not only more efficiently stored, but also much more usable.
mehr erfahren
