Datenversteher: Durch intelligente Graphdatenbanken Unternehmensdaten nutzen
Mit moderner Datenbanktechnologie die eigenen Daten intuitiv erfassen und verstehen
von DI Paul Heinzlreiter
Die große Stärke von Graphdatenbanken – das sind Datenbanken, die anhand von Graphen vernetzte Informationen in Form von Knoten und Kanten in Verbindung bringen und speichern – ist die umfangreiche Abbildung von Beziehungen zwischen Datenpunkten. Dies ermöglicht eine intuitive Abbildung vieler Real-World-Szenarien, die gerade während der letzten Jahre stark an Bedeutung gewonnen haben. Beispiele dafür sind die Modellierung von Beziehungen zwischen Personen in sozialen Netzwerken, die Erstellung von Kaufempfehlungen im E-Commerce, oder die Erkennung von betrügerischen Vorgängen im Finanzbereich. Neben diesen Anwendungsbereichen sind Graphdatenbanken auch in den Bereichen der industriellen Fertigung, der Verkehrsdatenanalyse oder der IT-Infrastrukturüberwachung für die Ermittlung kausaler Zusammenhänge hilfreich.
Inhalt
Graphdatenbanken im Vergleich zu relationalen Datenbanken
Der Weg zum besseren Datenverständnis
Use Case
Autor
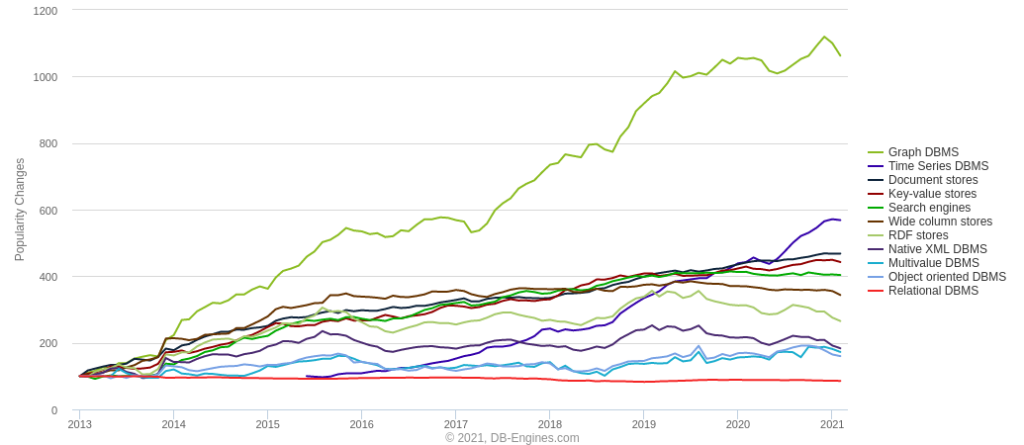
Laut einer Untersuchung über die Beliebtheit von Datenbankkategorien (https://db-engines.com/en/ranking_categories) stellen Graphdatenbanken die über die letzten Jahre die am schnellsten wachsende Kategorie von Datenbanktechnologien dar. Graphdatenbanken repräsentieren ihre Daten als Mengen von Knoten und Kanten, wobei Knoten mit Attributen versehene Datenobjekte darstellen, während die Kanten die Verknüpfungen zwischen den Objekten repräsentieren.
Graphdatenbanken im Vergleich zu relationalen Datenbanken
Relationale Datenbanken sind ausgezeichnet dafür geeignet, tabellarische Strukturen abzubilden, wie sie beispielsweise im kaufmännischen Bereich gängig sind. Durch den Einsatz der dritten Normalform werden die Daten nach den Objekten die sie beschreiben klar getrennt in Tabellen abgelegt, wobei andere Objekte, mit denen sie in Beziehung stehen, über Fremdschlüssel referenziert werden. Das Ziel hierbei ist unter anderem eine Datenduplikation zu vermeiden und eine Verknüpfung durch flexible Abfragen in der Structured Query Language (SQL) zu ermöglichen. Diese Anwendungen zeichnen sich weiters dadurch aus, dass ein einmal entworfenes Datenmodell üblicherweise über einen längeren Zeitraum konstant bleibt.
In Problemdomänen, in denen man primär an den Verknüpfungen zwischen den Daten interessiert ist, weist das relationale Datenmodell aber Schwachpunkte auf. Da Verknüpfungen über Fremdschlüsselbeziehungen abgebildet werden, müssen Abfragen oft als mehrstufige Joins umgesetzt werden, welche gerade bei großen Tabellen sehr laufzeitintensiv werden können. Zusätzlich treten in zahlreichen Anwendungsdomänen semistrukturierte Daten auf, deren Struktur sich über die Zeit ändert. Solche Daten lassen sich schwer in dem rigiden Datenmodell einer relationalen Datenbank abbilden.
Zusätzlich ermöglicht das flexiblere Datenmodell einer Graphdatenbank oft, die zu modellierende Realität direkter abzubilden und somit sowohl den Entwurf des Datenmodells als auch die darauf angewandten Abfragen intuitiver zu gestalten. Darüber hinaus ist es bei Änderungen in der Anwendungsdomäne leichter anpassbar, da der Graph ohne einschneidende Änderungen im Datenmodell erweitert werden kann.
Der Weg zum besseren Datenverständnis
Überall dort, wo Zusammenhänge zwischen Datenpunkten im Zentrum des Interesses stehen, bieten Graphdatenbanken eine solide Basis für die weitere Analyse. Sie ermöglichen eine direktere und flexiblere Abbildung der Problemdomäne als relationale Datenbanken. Darüber hinaus zeigen sie den Weg von den gesammelten Daten zur Beantwortung der Fragekategorie nach der Ursache von potenziellen oder aktuellen Problemen:
Warum ist dieses Teil ausgefallen?
Warum gibt es Engpässe und Preissteigerungen bei der Beschaffung von Teilen für die Produktion?
Warum schlägt eine Therapie bei einem Patienten besser an?
Warum ist diese Serverapplikation überlastet?
Use Cases
Use Case: Lieferketten-Modellierung
Komplexe Lieferketten können abgebildet und so potenzielle Engpässe oder Abhängigkeiten von einzelnen Lieferanten erkannt werden.
Use Case: Ursachenermittlung für Maschinenprobleme
Zusammenhänge zwischen Sensorwerten und Maschinenzuständen werden oft nur vermutet oder sind unbekannt. Eine Sammlung und zeitbasierte Verknüpfung von Daten in einer Graphdatenbank kann versteckte Korrelationen aufzeigen.
Use Case: Medizin
Graphdatenbanken können Zusammenhänge zwischen den Krankheitsgeschichten von Patienten und der Wirksamkeiten von Therapien aufzeigen. Ebenso können Wechselwirkungen von Medikamenten ermittelt werden.
Use Case: Pharmazeutische Industrie
Die Abbildung der Zusammenhänge zwischen biologischen und chemischen Daten kann die Entwicklung neuer Pharmazeutika beschleunigen.
Use Case: Nachvollziehbarkeit der Schaltungen in komplexen Anlagen
Von Verkehrbeeinflussungsanlagen bis zu Raffinerie- und Fabrikanlagen: Steuerungsalgorithmen nehmen automatisiert Schaltungen vor. Graphdatenbanken können helfen, diese für den Menschen nachvollziehbar zu machen, Fehler zu entdecken und die Effizienz solcher Anlagen zu steigern.
Use Case: Überwachung und Optimierung von IT-Anlagen
Parameter von Servern und Applikation können automatisiert gesammelt werden. Basierend darauf können Graphdatenbanken eingesetzt werden, um transitive Abhängigkeiten zwischen Diensten sowie Überlastungen oder kritische Elemente in IT-Infrastrukturen zu erkennen.
Die RISC Software GmbH unterstützt Sie auf jeder Stufe Ihres Prozesses, größtmöglichen Wert aus Ihren Daten zu generieren. Dies schließt nach Wunsch auch die Wahl der für Ihr Anliegen passenden Werkzeuge – wie beispielsweise eine Graphdatenbank – ein. Unternehmen, die bis jetzt noch keine durchgängige Datenerfassung haben oder ihre Daten noch nicht für solche Aufgaben nutzen, haben dabei die Möglichkeit, den Wert, den sie aus ihren Daten ziehen, schrittweise zu steigern.