Wie sicheres Chatten mit sensiblen Unternehmensdaten möglich wird
von Lukas Fallmann und Sandra Wartner, MSc
Künstliche Intelligenz (KI) revolutioniert nicht nur den privaten Alltag, sondern entfaltet auch im Unternehmensumfeld ihr enormes Potenzial. Durch die (Teil-)Automatisierung von Aufgaben wie der Erstellung von Dokumenten können Workflows verbessert werden. Auch der Kundenservice kann durch KI-gestützte Personalisierung optimiert werden. Die Bereitstellung von Daten-Insights durch KI-Systeme hilft ebenfalls, Abläufe zu optimieren. Große Sprachmodelle (Large Language Models, kurz LLMs) wie ChatGPT bieten dafür eine breite Palette vielversprechender Anwendungen. Gleichzeitig bleibt allerdings häufig die Sorge um den Umgang mit sensiblen Informationen (z. B. Betriebsgeheimnisse oder persönliche Daten) ein Hindernis für die breite Akzeptanz dieser Technologien. Das Thema Datensicherheit ist bei großen Anbieter*innen meist undurchsichtig oder nicht gegeben.
Inhaltsverzeichnis
Meine Daten, meine Regeln: Datenschutz und Transparenz in der Nutzung von LLMs
Spezifische Informationen für spezifische Fragen – Retrieval Augmentation Generation (RAG)
1) Finetuning
2) Retrieval Augmented Generation
Evaluierung von RAG-Systemen
Ausblick & Fazit
Referenzen
Weiterlesen
Autor*innen
Die rasanten KI-Fortschritte haben inzwischen auch die Qualität von öffentlich verfügbaren Modell-Alternativen erheblich verbessert. Unternehmen können leistungsstarke Modelle nun auch sicher und gezielt mit firmeneigenen Daten in einer eigens gewählten Infrastruktur nutzen. Diese neuen Möglichkeiten gewährleisten auch eine transparente und vertrauenswürdige Nutzung, die den Schutz schützenswerter Informationen in den Vordergrund stellt. Wie das auf technischer Ebene möglich wird und worauf es ankommt, erfahren Sie in diesem Artikel.
Meine Daten, meine Regeln: Datenschutz und Transparenz in der Nutzung von LLMs
Allgemein kann zwischen Open-Source- und Closed-Source-Modellen unterschieden werden. Wie der Name schon vermuten lässt, sind Closed-Source LLMs Modelle, bei denen die Implementierungsdetails nicht öffentlich zugänglich sind. Dies hat die direkte Folge, dass hierbei nicht klar nachvollziehbar ist, ob und wie die eingegebenen Anfragen und Modellantworten von LLM Anbieter*innen weiter verwendet werden. Der Vorteil von Closed-Source Applikationen ist jedoch der, dass mit wenig bis gar keinem Entwicklungsaufwand schnell Unternehmensprozesse verbessert werden können.
Im Kontrast dazu bieten Open-Source-Modelle wie z. B. jene von Mistral AI weitaus mehr Transparenz. Wesentliche Modellinformationen sind dabei einsehbar und damit besser nachvollziehbar. Mit Informationen zur Architektur und Modellgewichten (in welchen das erlernte Wissen kodiert ist) kann das Modell auch mit unternehmensspezifischen Daten weiterentwickelt (trainiert) werden. Dadurch kann dessen Performance für einen speziellen Anwendungsfall, eine spezielle Sprache oder Domäne verbessert werden. Die Verwendung von Open-Source-Modellen bietet dahingehend viele Vorteile, jedoch geht dies mit einem erhöhten Aufwand und notwendigem technischen Know-how einher. Oft müssen solche Modelle in einer speziellen Infrastruktur mit ausreichend Rechenressourcen gehostet werden und der Supportaufwand ist bedeutend höher.
Nachfolgende Tabelle zeigt in ausgewählten Funktionen eine Gegenüberstellung:
Funktion
Closed Source
Open Source
Transparenz der Modellinformationen (z.B. Architektur, Modellgewichte, Trainingsdaten)
Nicht verfügbar
Öffentlich zugänglich
Datenschutz
Abhängig von den Sicherheitsvorkehrungen und Logging-Mechanismen der Anbieter*innen
Volle Transparenz und Kontrolle über die Datensicherheit durch eigens implementierte Sicherheitsvorkehrungen
Personalisierung
Anpassungsmöglichkeiten eingeschränkt (oftmals eingeschränkt durch Prompt Engineering)
Kann nach Belieben angepasst werden (z.B. durch weiteres Modelltraining)
Entwicklungsaufwand
Meist geringer Setup- bzw. Konfigurationsaufwand
Höherer Initialaufwand, muss eventuell selbst gehostet werde
Kosten
Laufende Lizenzkosten (zumeist pay-per-use)
Keine laufenden Lizenzkosten, dafür (Anschaffungs-)Kosten in Form von Infrastruktur- bzw. Rechenressourcen (on premise, Cloud-GPUs,…)
Beispiele
ChatGPT (OpenAI), Gemini (Google)
Mistral- bzw. Mixtral (Mistral-AI), Phi3 (Microsoft), Llama3 (Meta-AI)
Spezifische Informationen für spezifische Fragen – Retrieval Augmentation Generation (RAG)
LLMs sind herausragend darin, Fragen und Tasks zu bearbeiten. Allerdings stoßen native Modelle wie ChatGPT oder Gemini bei der Beantwortung unternehmensspezifischer Fragen meist an ihre Grenzen. LLMs sind auf jene Informationen limitiert, mit denen sie trainiert worden sind. Um die Abfrage von firmenspezifischen Informationen zu ermöglichen, gibt es zwei verschiedene Ansätze.
1) Finetuning
Die rechenintensive Möglichkeit ist, ein vorhandenes Open-Source Modell mit firmeninternen Informationen weiter zu trainieren (finetunen). Durch Finetuning kann das Modell domänenspezifisches Wissen wie zum Beispiel medizinische Fachbegriffe in den Wortschatz mitaufnehmen. Dies ist allerdings kostspielig und unflexibel, da neue Informationen nur durch ein erneutes Trainieren hinzugefügt werden können und besonders problematisch, wenn sich Informationen häufig ändern.
2) Retrieval Augmented Generation
Mehr Flexibilität kann dabei über “Retrieval Augmented Generation“ (kurz RAG) [1] erreicht werden, wobei bei diesem Ansatz das einzubindende Wissen in einem jederzeit anpassbaren, externen Datenspeicher gehalten wird. Basierend auf einer Anfrage an das LLM wird in einem Vorschritt die relevante Information aus der Wissensbasis extrahiert („retrieval“) und dem LLM als Kontext („augmented“) zur Beantwortung der Frage („generation“) zur Verfügung gestellt. Für diesen Prozess ist es nicht notwendig, dass das LLM im Vorfeld mit den Daten trainiert worden ist.
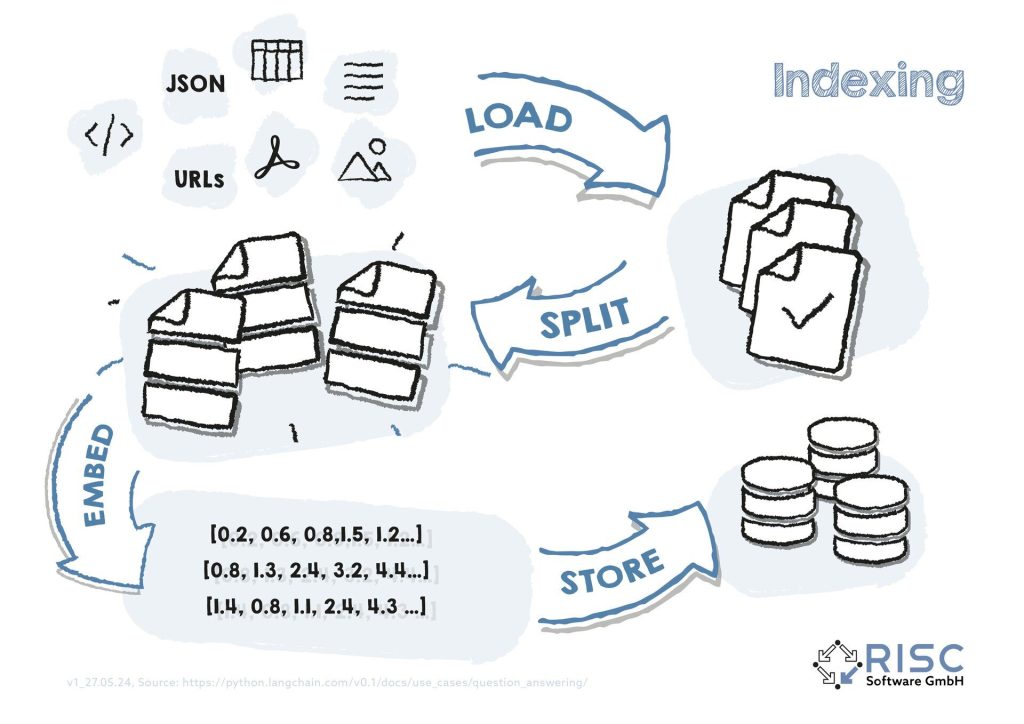
Der Aufbau der Wissensbasis erfolgt über den sogenannten Indexing Prozess (siehe auch Abb. 1). Beim Indexing wird jedes einzelne Dokument (z.B. Text-, HTML-, PDF-Dateien) geladen („load“) und so aufbereitet, dass kleinere, semantisch zusammenhängende Teildokumente entstehen („split“). Als nächstes wird mithilfe eines eigenen Machine Learning Models eine maschinenlesbare Zahlenrepräsentation (ein Vektor bzw. sogenanntes „Embedding“) der Teildokumente erstellt („embed“). Dieses „Embedding“ enthält relevante, maschinenlesbare Informationen und wird in einer speziellen Vektor-Datenbank gespeichert („store“).
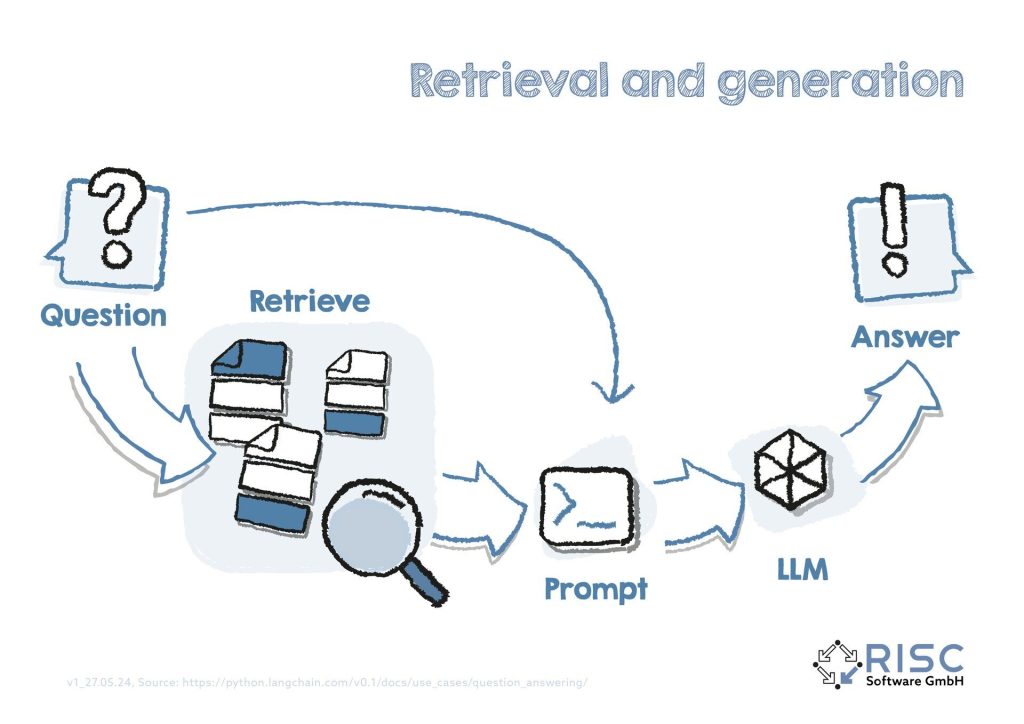
Abbildung 1: Wird eine Frage an das RAG-System gestellt, muss diese ebenfalls in ein maschinenlesbares Embedding überführt werden. Mit Hilfe von Algorithmen zur Ähnlichkeitsberechnung zwischen dem Frage-Embedding und den Dokument-Embeddings können somit mit geringem Rechenaufwand schnell die ähnlichsten Dokumente in der Wissensdatenbank gesucht, die zugehörigen Originaltexte automatisch in der Prompt eingefügt und das LLM für die kontextbasierte Antwortgenerierung aufgerufen werden (siehe auch Abbildung 2).
Abbildung 2: Die Implementierung eines solchen Systems erfordert inital einiges an Aufwand, da es zahlreiche Stellschrauben zu feinadjustieren gibt, um die optimale Funktionsweise zu finden, wie bspw. das Modell selbst, unterschiedliche Datenquellen, Sprachen oder das Einbinden von Tabellen oder Bildern. Der Aufwand lohnt sich jedoch häufig sehr schnell und bietet optimale Ausgangsbedingungen für weitere Anwendungen, wie bspw. für einen Unternehmensinternen Q&A Bot. Die Wissensbasis bilden dabei unternehmensrelevante Dokumente, die synchron mit der Vektor-Datenbank gehalten werden können und der Q&A Bot damit immer auf dem aktuellsten Wissensstand bleibt.
Evaluierung von RAG-Systemen
Es liegt in der Natur der Sprache, dass unterschiedliche Formulierungen die gleiche Kernaussage haben können, was auch den automatischen Vergleich von Texten sehr schwierig gestaltet. Eine weitere Herausforderung liegt darin, einzelne RAG Konfigurationen quantitativ miteinander vergleichen zu können. Auch da es sich bei den vom LLM generierten Antworten nur selten um ganz klar falsche oder korrekte Antworten handelt, bedarf es einer standardisierten Evaluierungsmethode mit klar definierten Metriken.
Frage
LLM Antwort
Tatsächliche Antwort
Answer Correctness
Wer ist CEO der RISC Software GmbH?
Wolfgang Freiseisen ist CEO der RISC Software GmbH.
Wolfgang Freiseisen ist CEO der RISC Software GmbH.
1.0
Wer ist CEO der RISC Software GmbH?
Max Mustermann ist CEO bei RISC Software.
Wolfgang Freiseisen ist CEO der RISC Software GmbH.
0.16
Wer ist CEO der RISC Software GmbH?
Wolfgang Freiseisen ist Geschäftsführer der RISC Software GmbH.
Wolfgang Freiseisen ist CEO der RISC Software GmbH.
0.99
Ausblick & Fazit
Mit RAG können einige unternehmensspezifische Anwendungsfälle umgesetzt werden. Wie für alle KI-basierten Systeme gilt, ist auch in RAG-Systemen die Qualität der generierten Antworten stark von der Konfiguration und der Qualität der bereitgestellten Daten abhängig. Sauberes Datenqualitätsmanagement zahlt sich aus, denn Falschinformationen oder Widersprüche in der Wissensdatenbank führen häufig nicht nur zu einer schlechteren Qualität der Modellantworten, sondern schleichen sich auch häufig unbemerkt in andere Prozesse ein (siehe auch [3] und [4]).
Eine Ausweitung des Wissens auf weitere Informationsquellen kann auch mit Hilfe von sogenannten „Agents“ geschaffen werden. Agents sind fortgeschrittene KI-Systeme, die für die Erstellung komplexer Texte entwickelt wurden, die sequenzielle Schlussfolgerungen erfordern. Agenten können dabei spezifische Aufgaben intelligent an andere Experten-Systeme und Schnittstellen weiterleiten, die für eine spezielle Anfrage oder Aufgabe am geeignetsten ist. So könnte zum Beispiel die Anfrage “Durchsuche das Web zum Thema RISC Software” an eine Web Search Komponente weitergeleitet werden oder eine Anfrage zur Lösung eines komplexen mathematischen Problems direkt an ein extra dafür trainiertes Model weitergeleitet werden. Des Weiteren können Agents in Kombination mit Evaluierungs-Tools wie z.B. Ragas verwendet werden, um Antworten mit geringer Qualität neu zu generieren. Durch solche Tools wird es in Zukunft noch besser gelingen, Unternehmensprozesse zu optimieren.
Referenzen
[1] https://arxiv.org/abs/2312.10997 Gao, Yunfan, et al. „Retrieval-augmented generation for large language models: A survey.“ arXiv preprint arXiv:2312.10997 (2023).
[2] https://arxiv.org/abs/2309.15217 Es, Shahul, et al. „Ragas: Automated evaluation of retrieval augmented generation.“ arXiv preprint arXiv:2309.15217 (2023).