SafeSign – Das sichere Verkehrszeichen 4.1
Wie eine Künstliche Intelligenz Verkehrszeichen sieht
mehr erfahren
Die RISC Software GmbH hat gemeinsam mit der Direktion für Straßenbau und Verkehr des Landes Oberösterreich ein Projekt zur automatisierten Erkennung und präzisen Lokalisierung von Verkehrszeichen umgesetzt. Dabei testeten die Partner, wie sich bestehende RGB-Videodaten des RoadSTAR-Aufzeichnungsfahrzeugs für KI-gestützte Detektion, Klassifikation und Verortung nutzen lassen. Mithilfe von Machine Learning und Stereokamera-Analysen entstand ein System, das Verkehrszeichen zuverlässig erkennt und deren Position in Echtweltkoordinaten bestimmt. Dadurch verbessert sich die Verwaltung von Straßendatenbanken erheblich, was wiederum eine Grundlage für künftige Innovationen in der Verkehrsüberwachung schafft.
Das Land Oberösterreich erfasst regelmäßig Straßenzustände mit dem RoadSTAR-Aufzeichnungsfahrzeug des Austrian Institute of Technology. Neben Sensorik kommt ein kalibriertes Stereokamerasystem zum Einsatz, das Befahrungen in RGB-Videos dokumentiert. Die RISC Software GmbH prüfte, wie diese Videos für die automatische Detektion, Klassifikation und Verortung von Verkehrszeichen eingesetzt werden können. Das System muss also erkennen, wo sich ein Verkehrszeichen im Bild befindet, welcher Typ es ist und wo es sich in der realen Welt befindet.

Abbildung 1: Schritte der Verkehrszeichenerkennung und -verortung
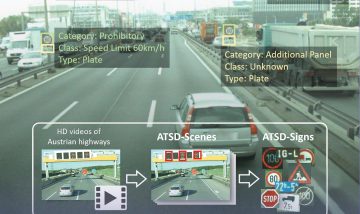
Im ersten Schritt galt es, Verkehrszeichen verlässlich zu erfassen. Dafür entstand ein repräsentativer Datensatz für den österreichischen Straßenraum mit mehreren tausend Bildern. Einige stammten aus öffentlichen Quellen, andere annotierten die Forschenden neu. Besonders wertvoll erwies sich der „Austrian Highway Traffic Sign Data Set (ATSD)“, der im früheren Forschungsprojekt SafeSign erstellt wurde.
Auf Basis dieses Datensatzes trainierte das Team ein Modell, das sowohl Geschwindigkeit als auch Genauigkeit erfüllt. Das Detektionsmodell liefert die Positionen der Verkehrszeichen in jedem Video-Frame als Bounding Boxes sowie deren Klassenzugehörigkeit, etwa „Vorrang geben“ (siehe auch Abbildung 2). Damit legte das Modell die Grundlage für die exakte räumliche Verortung.

Abbildung 2: Beispielbild mit detektierten Verkehrszeichen. Jedes Verkehrszeichen ist von einer Bounding Box umfasst, zusätzlich wird noch die Konfidenz des Modells (hier 100%) und die Klasse angezeigt.
Ein Stereokamera System erlaubt, die Tiefe eines Punktes im Raum zu schätzen – vorausgesetzt, man kennt die korrespondierende Position in beiden Bilder. Dazu werden Bereiche beider Bilder abgeglichen, um pixelgenaue Korrespondenzen zu indentifizieren (siehe Abbildung 3). Damit kann der Abstand der Punkte zwischen dem linken und rechten Bild berechnet werden – die Disparität (in Pixel). Ein vertrautes Beispiel dafür ist die menschliche Tiefenschätzung: Unsere Augen haben einen konstanten Abstand zueinander und nehmen daher leicht unterschiedliche Bilder auf. Wenn wir auf einen Finger blicken und abwechselnd das linke und rechte Auge schließen, sehen wir, dass der Finger seine relative Position abhängig von der Distanz zum Finger ändert – je weiter weg, desto weniger ist die Verschiebung. Diese Verschiebung ist die Disparität, die unser Gehirn nutzt, um die Entfernung des Fingers zu bestimmen.
Da in einem Stereokamerasystem der Abstand der Kameras zueinander (die Baseline) und die Kameraeigenschaften bekannt sind, kann die Disparität in eine Entfernung umgerechnet werden. Und sobald diese relative Position zur Kamera ermittelt wird, können ebenfalls die Echtweltkoordinaten berechnet werden – sofern die GPS Position der Kamera, wie bei dem RoadStar Truck, bekannt ist.

Abbildung 3: Durch Matching werde möglichst pixelgenaue Positionen im linken und rechten Bild identifiziert.
In einem nächsten Schritt werden dann alle Instanzen desselben Verkehrszeichens gruppiert. Das ist notwendig, da beim Vorbeifahren jedes Verkehrszeichen mehrfach aufgezeichnet wird. Jedes muss natürlich verlässlich wiedererkannt werden, besonders wenn mehrere gleiche VZ im Bild sind. Dafür werden die geschätzten Echtweltkoordinaten verwendet, womit auch zugleich Außreißer identifiziert werden können, die inkorrekt verortet wurden (z.B. durch falsche Punktpaarung aufgrund von teilweise verdeckten Zeichen).
In einem finalen Schritt werden noch Verkehrszeichen betrachtet, die Information in Textform beinhalten. Um etwaigen Text zu extrahieren, wird auf Texterkennungsmodelle für Optical Character Recognition (OCR) zurückgegriffen. Dafür gibt es bereits viele vortrainierte Modelle wie z.B: tesseract, aber auch Vision-Language-Modelle wie Florence-2, die mit entsprechender Vorverarbeitung sehr gute Ergebnisse liefern. Siehe Abbildung 4 für ein Beispiel von Textextraktion auf Km-Tafeln entlang der Straße, die gerade aufgrund ihrer geringen Größe besonders herausfordernd sind.

Abbildung 4: Beispiele für OCR, über dem Bildausschnitt wird der erkannte Text angezeigt.
Alle Schritte zusammen liefern dann eine Pipeline, die automatisiert über eine beliebige Anzahl von Videos vorhandene Verkehrszeichen detektieren und verorten kann. Die generierten Daten stehen dann für Visualisierungen, aber auch für Identifikation problematischer VZ bereit. Und – am wichtigsten – für die Verbesserung der Positionsdaten von Verkehrszeichen in den Straßendatenbanken des Landes.


Data Scientist & Researcher