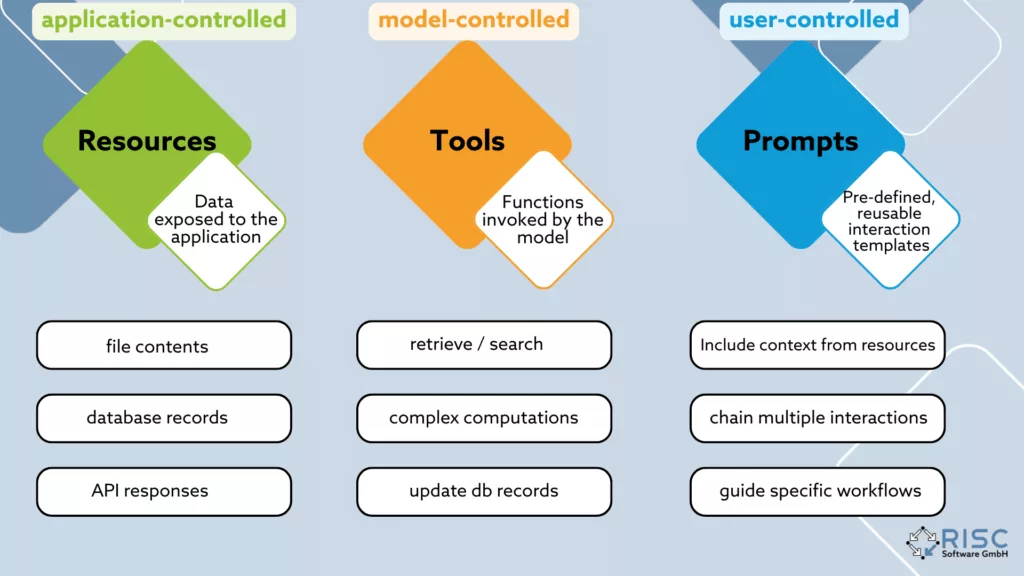
MCP-Server: Das verbindende Gewebe zwischen KI, Daten und Werkzeugen
von Patrick Kraus-Füreder
Wie das Model Context Protocol KI-Systeme sicher mit Dateien, APIs und technischen Systemen verbindet
KI-Systeme werden zunehmend zu aktiven Akteuren: Sie lesen nicht nur Daten, sondern lösen Workflows aus, bearbeiten Tickets, analysieren Messwerte und interagieren direkt mit technischen Systemen. Damit solche Anwendungen sicher, nachvollziehbar und systemübergreifend funktionieren, braucht es einen Standard, der Modelle zuverlässig mit Dateien, APIs, Repositories oder Edge-Geräten verbindet. Genau diese Rolle übernimmt das Model Context Protocol (MCP) – ein offenes Protokoll, das KI-Clients und Unternehmenssysteme sauber entkoppelt und über klar definierte Tools, Ressourcen und Policies verbindet. Der folgende Artikel zeigt, warum MCP für moderne Industrie-, Engineering- und IT-Umgebungen relevant wird, wie MCP-Server funktionieren und welche Architektur- und Sicherheitsprinzipien aus der Praxis entscheidend sind.
Inhalt
Warum MCP jetzt relevant ist
Was MCP ist – und was ein MCP-Server tut
Architektur – vom Client-Host bis zur Server-Topologie
Sicherheit, Governance & Qualität – mehr als „nur ein Tool-Call“
Industrial Grade: Edge, Latenz & Datenhoheit
Interoperabilität & Ökosystem
Typische Einsatzfelder (Industrie)
Leistungs- und Betriebsaspekte
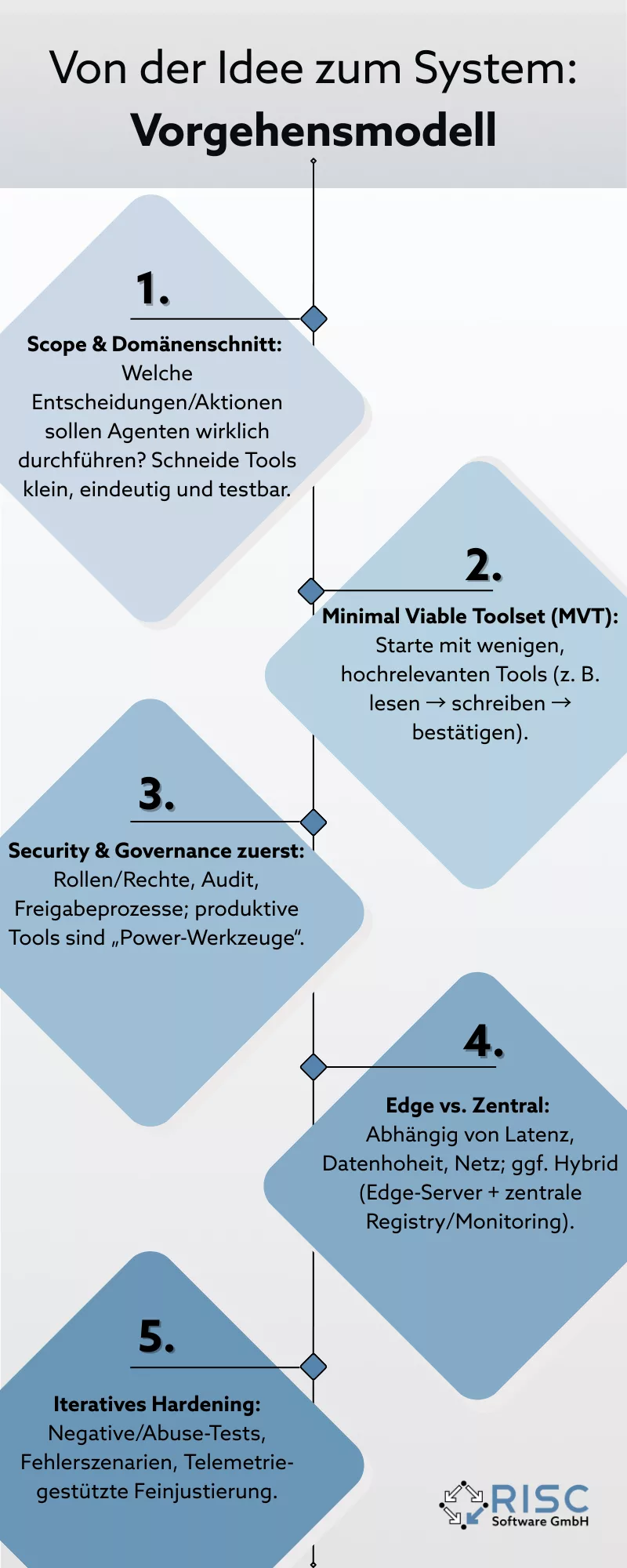
Von der Idee zum System: Vorgehensmodell
Macht MCP für uns Sinn?
Quellen (Auswahl)
Kontakt
Autor
Weiterlesen
Kurz gesagt: Moderne KI-Anwendungen brauchen mehr als ein starkes Modell. Sie benötigen verlässlichen, sicheren und standardisierten Zugriff auf Datenquellen, Werkzeuge und Workflows – on-prem, in der Cloud und zunehmend am Edge. Genau hier setzt das Model Context Protocol (MCP) an: ein offener Standard, über den KI-Clients (etwa Claude, Copilot-Umgebungen oder eigene Agenten) kontrolliert mit externen Systemen interagieren. MCP-Server sind die Gegenstücke auf der Systemseite: Sie exponieren Daten, Tools und Ressourcen in klar definierten, auditierbaren Schnittstellen. Man kann sich MCP als „USB-C für KI-Apps“ vorstellen – einheitlicher Stecker, viele Geräte.
Warum MCP jetzt relevant ist
In den letzten 18-24 Monaten haben sich drei Entwicklungen überlagert, die MCP jetzt strategisch relevant machen. Erstens stehen mit der offiziellen Spezifikation und stabilen Referenz-Stacks erstmals konsolidierte Grundlagen zur Verfügung. Zweitens verlangen Unternehmen zunehmend nach KI-Assistenten, die nicht nur Texte verarbeiten, sondern konkrete Aktionen ausführen können – etwa Tickets erstellen, Repositories verändern oder Berichte automatisiert ablegen. Drittens haben Edge-Deployments einen Reifegrad erreicht, der stabile Latenzen und leistungsfähige Hardware direkt an Maschine oder Linie bietet. Damit wird MCP technisch wie wirtschaftlich zu einer realistischen Option und nicht bloß zu einer interessanten Demo. Parallel dazu professionalisieren erste Ökosystem-Bausteine den Betrieb: öffentlich zugängliche Dokumentationen und Spezifikationen, offizielle Beispiel- und Produkt-Server wie der GitHub MCP Server sowie erste Registries zur Entdeckung kompatibler Server reduzieren den Integrationsaufwand und schaffen Sicherheit bei der Tool-Auswahl.
Was MCP ist – und was ein MCP-Server tut
MCP standardisiert die Verbindung zwischen einem Client – also einer KI-Anwendung oder einem Agenten – und einem Server, der als Adapter ins bestehende System wirkt. Ein MCP-Server bündelt dafür ausführbare Funktionen mit definierten Schnittstellen, stellt strukturierte Lesezugriffe auf interne Datenquellen bereit und kann zusätzlich kuratierte Prompt-Bausteine anbieten, um Interaktionen konsistent zu halten. Die technische Basis bildet ein klar beschriebenes Protokoll auf JSON-RPC-Ebene, ergänzt um Schemas und Transportkanäle für lokale Ausführung über stdio sowie für entfernte Anbindung per HTTP, WebSocket oder SSE. Für Unternehmen bedeutet das einen reproduzierbaren Interaktionsrahmen, saubere Rückverfolgbarkeit der Ergebnisse und einen klaren Ort, an dem Zugriffs- und Sicherheitsregeln durchgesetzt werden können.
Architektur – vom Client-Host bis zur Server-Topologie
Ein typisches MCP-Setup besteht aus einer KI-fähigen Anwendung – etwa einem IDE-Plugin, einem Chat-Frontend oder einer Desktop-App, die als MCP-Client fungiert und alle Toolaufrufe auslöst. Beispiele dafür sind Claude Desktop oder KOALA. Dahinter stehen ein oder mehrere MCP-Server, die jeweils eine fachliche Domäne kapseln, etwa GitHub, eine Dateiablage oder ein internes MES, und dort klar benannte Tools und Ressourcen bereitstellen. Die Kommunikation läuft entweder lokal über stdio, was sich besonders für Desktop- und Entwickler-Workflows anbietet, oder netzwerkbasiert über HTTP, WebSocket oder SSE, wenn zentrale oder Edge-Server angebunden sind. Eine klare Schema- und Versionsführung stellt sicher, dass Tool-Signaturen, Parametertypen und Fehlerrückgaben stabil bleiben und sich ohne Brüche weiterentwickeln lassen. Auf dieser Grundlage haben sich in der Praxis drei Architekturmuster für MCP-Infrastrukturen bewährt, die eng an gängige Microservice- und API-Designprinzipien anschließen.
Muster
Beschreibung
Entsprechung in Softwarearchitektur
Quelle
Adapter-Server
Bindet ein bestehendes System oder eine API an das MCP-Protokoll an. Reduziert Integrationsaufwand, trennt Logik und Schnittstelle.
Sicherheit, Governance & Qualität – mehr als „nur ein Tool-Call“
Mit MCP wächst die operative Reichweite eines Agenten, und damit steigen die Anforderungen an Sicherheit, Governance und Qualität deutlich. Zentral ist eine präzise Steuerung von Authentifizierung und Autorisierung, sodass nur jene Funktionen freigeschaltet werden, die in der jeweiligen Umgebung wirklich notwendig sind und exakt die erlaubten Aktionen abdecken. Genauso wichtig ist eine konsequente Validierung aller Eingaben und Ausgaben: strikte Schemata, saubere Parametrisierung und ein Fail-Closed-Verhalten verhindern, dass Agenten unklare Zustände oder Fehlinterpretationen ausnutzen oder weiterreichen. Produktive Systeme brauchen zudem vollständige Auditierbarkeit mit lückenlosen Logs, klaren Revisionspfaden und einer Alarmierung bei Policy-Verstößen. Ergänzend dazu müssen robuste Test- und Härtungsverfahren etabliert werden – einschließlich negativer Tests gegen prompt-induzierte Fehlaktionen, mögliche Manipulationen von Tool-Definitionen oder den Missbrauch generischer Funktionen. Erste Sicherheitsanalysen zeigen, dass MCP eigene Angriffspunkte mitbringt; ein Security-by-Design-Ansatz ist daher unverzichtbar.
Industrial Grade: Edge, Latenz & Datenhoheit
Viele industrielle Workflows verlangen niedrige Latenz und hohe Verfügbarkeit – ideal für Edge-MCP-Server nahe der Maschine (z. B. an der Linie), kombiniert mit zentralen Services für Registry, Observability und Policy. Vorteil: Daten verlassen die Zone nicht, Entscheidungen bleiben schnell, und die Integration in OT/IT-Netze bleibt kontrollierbar. Die jüngsten Integrationspfade in gängige KI-Clients verbessern zudem das Remote-Server-Modell, wenn Edge nicht nötig ist.
Interoperabilität & Ökosystem
Das offizielle MCP-Portal sowie die GitHub Organisation modelcontextprotocol bündeln Spezifikation, SDKs und Dokumentation des Model Context Protocol. Wachsende Listen von Beispiel- und Produkt-Servern erleichtern die Auswahl und Integration. Ein prominentes Referenzbeispiel ist der GitHub MCP Server, der zeigt, wie Infrastruktur-Plattformen native MCP-Brücken implementieren können. Parallel entstehen Community-Initiativen wie „Awesome MCP“-Listen und öffentliche Registries, die Discovery, Kompatibilität und Update-Management strukturieren.parallel entstehen Community-Sammlungen („Awesome“-Listen) und Registries, die Discovery, Kompatibilität und Updates strukturieren. Das verkürzt Proof-of-Concept-Phasen und reduziert Vendor-Lock-in.
Typische Einsatzfelder (Industrie)
Im Industriebereich zeigt sich MCP vor allem dort als stark, wo strukturierte, auditierbare und wiederholbare Interaktionen zwischen KI-Agenten und bestehenden Systemen nötig sind. Ein großer Block betrifft den Wissenszugriff: technische Handbücher, Prüfpläne oder Change-Logs lassen sich über einheitliche Ressourcen- und Suchtools anbinden, und sobald spezielle Anforderungen auftreten, reicht ein klassisches RAG-System meist nicht mehr aus – ein dediziertes MCP-Tool wird dann zum logischen nächsten Schritt. In Qualitätssicherungs- und QS-Pipelines können Agenten Messdaten abrufen, Bild- oder Signalanalysen starten, Ergebnisse versioniert ablegen und bei Abweichungen automatisiert eskalieren. Im Engineering ermöglichen MCP-Server den kontrollierten Zugriff auf Repositories, das Erzeugen von Issues und PRs oder das Prüfen von Build-Artefakten – inklusive Rollen- und Rechteschutz direkt im Interaktionspfad. Auch Betrieb und IT-Service-Management profitieren: Runbooks, Tickets, CMDB-Abfragen oder Telemetriedaten lassen sich einheitlich ausführen und dokumentieren, statt auf heterogene Integrationsscripts angewiesen zu sein. Viele dieser Muster tauchen bereits in Dokumentation, Produktankündigungen und Beispiel-Repositories auf, was das Implementierungsrisiko reduziert und klare Vorlagen für eigene Domänen liefert.
Leistungs- und Betriebsaspekte
Die Performance eines MCP-Systems wird im Wesentlichen von drei Faktoren bestimmt: der Vor- und Nachverarbeitung auf CPU-Ebene, der Latenz der angebundenen Backends und Netzwerke sowie – falls innerhalb des Servers Modelle ausgeführt oder komplexe Transformationen durchgeführt werden – der lokalen GPU- oder NPU-Last. Für produktive Umgebungen hat sich gezeigt, dass eine konsequent asynchrone Architektur mit klar definierten Timeouts und Circuit Breakern pro Tool entscheidend ist. Ebenso wichtig ist eine Observability-Strategie, die Latenzen, Fehlerraten und Tool-Nutzungsmuster standardmäßig erfasst und durch strukturierte Logs mit User- oder Session-Daten korreliert. Stabilität über längere Betriebsphasen entsteht durch saubere Schema-Versionierung und kompatible Migrationspfade, damit Client-Updates nicht ungeplant Prozesse blockieren. Ergänzend erhöhen Resilienzmechanismen wie Fallback-Varianten eines Tools – etwa read-only statt write – oder Dry-Run-Modi für sensible Operationen die Betriebssicherheit. Die offizielle Dokumentation sowie technische Beiträge von Plattformen wie GitHub oder Anthropic liefern hierfür bereits belastbare Grundlagen.