Vertragsverhandlungen binden in Unternehmen viel Zeit und Ressourcen. Große Sprachmodelle analysieren und vergleichen Verträge heute automatisiert und können mit aktuell verfügbaren Lösungen auf lokaler Infrastruktur betrieben werden.
von DI (FH) Stephan Leitner
Inhalt
Vom Rohtext zur strukturierten Analyse: Was vor der KI passiert
RAG statt Raten: Die Lösung bei langen Verträgen
Embeddings: Präszision im Vertragsvergleich
Halluzinationen kontrollieren: Vertrauen mit Grenzen
On-Premises statt Cloud: Kontrolle über die Infrastruktur ist entscheidend
Integration in bestehende Systeme: Der nächste Schritt zur unternehmensweiten Lösung
Fazit
Autor
Kontakt
Ein neuer 120-seitiger Rahmenvertrag, eine kurze Prüffrist, ein überlastetes Rechtsteam. Dieses Szenario ist im B2B Bereich allgegenwärtig. Large Language Models (LLMs) können diesen Prozess grundlegend verändern, vorausgesetzt die technische Umsetzung stimmt. Wer die technischen Grundlagen versteht, trifft fundiertere Entscheidungen – bei der Infrastruktur, bei der Risikobewertung und beim Aufbau einer nachhaltigen Lösung zur Vertragsanalyse.
Vom Rohtext zur strukturierten Analyse: Was vor der KI passiert
Bevor ein LLM einen Vertrag bearbeiten kann, muss dieser in einem geeigneten Format vorliegen. In der Praxis sind Verträge oft nur als eingescannte PDFs oder schlecht strukturierte Word-Dokumente vorhanden. Eingescannte PDFs sind für eine KI nur Bilder ohne maschinenlesbaren Text.
Hier kommt Optical Character Recognition (OCR) zum Einsatz, das Zeichen in Bildern erkennt und diese in maschinenlesbaren Text umwandelt. Moderne OCR-Lösungen erreichen dabei hohe Erkennungsraten, trotzdem können bei schlechter Scanqualität, handschriftlichen Anmerkungen oder komplexen Tabellen Fehler auftreten.
Deshalb ist die Vorverarbeitung ein oft unterschätzter Teil des Systems. Dazu zählen die Bereinigung von OCR-Fehlern, die Erkennung von Dokumentstruktur (Abschnitte, Klauseln, Anhänge) , die Verarbeitung von Tabellen und Bildern sowie die Normalisierung von Datumsformaten oder Währungsangaben.
RAG statt Raten: Die Lösung bei langen Verträgen
Ein zentrales technisches Limit von LLMs ist das Kontextfenster. Dabei handelt es sich um die maximale Textmenge, die ein Modell pro Anfrage verarbeiten kann. Aktuelle Modelle bewältigen zwar deutlich mehr als frühere Generationen, doch umfangreiche Vertragswerke mit Anhängen, Leistungsverzeichnissen und Rahmenvereinbarungen sprengen dieses Limit schnell, würde man versuchen alles in einer einzigen Abfrage zu verarbeiten.
Die Lösung heißt Retrieval-Augmented Generation (RAG). Das Prinzip ist elegant: Der gesamte Vertrag wird in kleinen Abschnitten (Chunks) in einer Vektordatenbank gespeichert. Stellt eine Nutzer*in eine Frage sucht das System zuerst die relevanten Textpassagen und übergibt sie mit der Frage an das LLM. Das Modell antwortet dann nur auf Basis dieser Passagen, nicht aus seinem allgemeinen Trainingswissen.
Das hat zwei entscheidende Vorteile. Erstens skaliert der Ansatz: Die Dokumentenlänge spielt keine Rolle mehr, weil immer nur relevante Abschnitte geladen werden. Zweitens ist die Antwort nachvollziehbar: Jede Aussage des LLMs lässt sich direkt auf eine konkrete Textstelle im Originaldokument zurückführen.
In der Praxis kombinieren viele Systeme RAG mit einer hierarchischen Dokumentenstruktur: Klauseln werden nicht nur als Fließtext gespeichert, sondern mit Metadaten versehen – etwa Klauseltyp, Vertragspartei oder Gültigkeitsdatum. Das macht gezielte Abfragen wie „Zeige alle Klauseln zur Vertragslaufzeit aus Lieferantenverträgen aus dem Jahr 2023″ erst möglich.
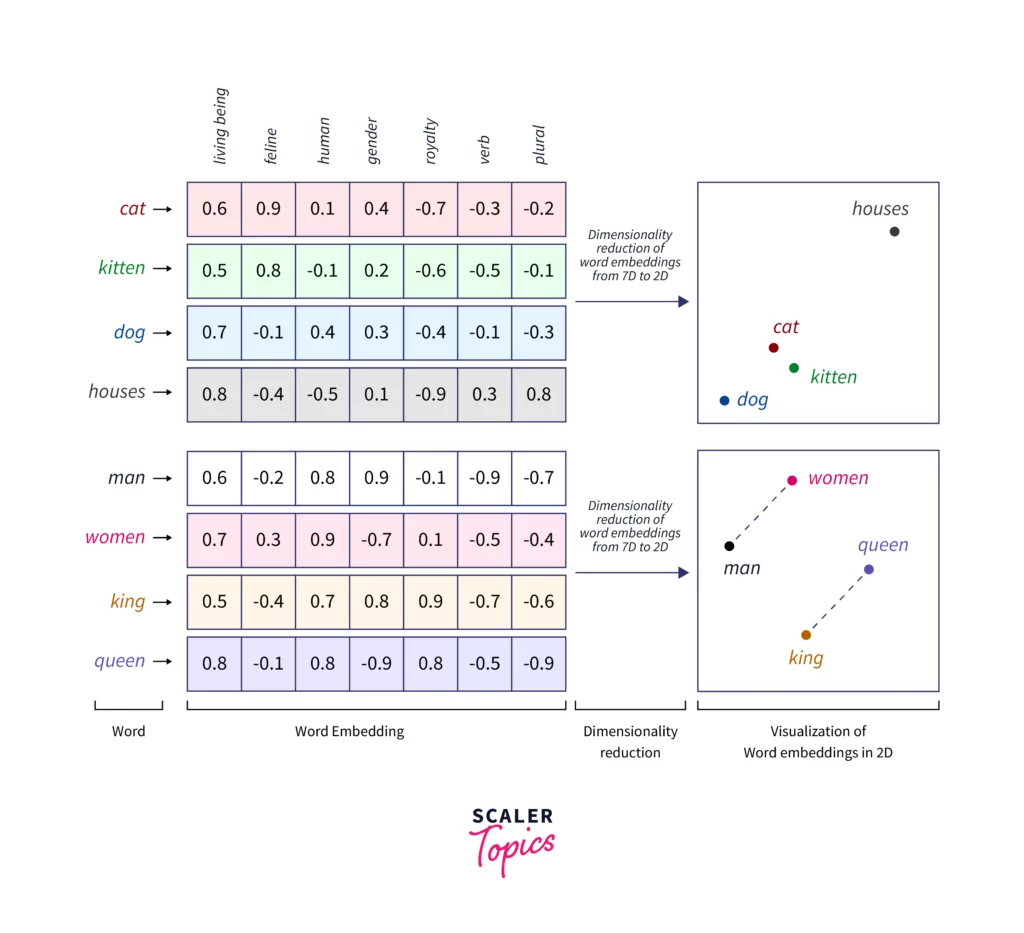
Embeddings: Präszision im Vertragsvergleich
Ein Anwendungsfall, bei dem LLMs besonders effizient unterstützen ist der Vergleich von Verträgen. Dabei können Abweichungen von einem internen Standard genauso erkannt werden wie Änderungen, die von einem Vertragspartner in Laufe der Verhandlungen in einem Vertrag vorgenommen wurden.
Eine simple Textsuche stößt hier schnell an Grenzen. Sie findet identische Wörter, aber keine inhaltlichen Ähnlichkeiten. Eine Klausel, die Haftung auf „direkte Schäden“ begrenzt, und eine andere, die „Folgeschäden ausschließt“, sind inhaltlich gleichbedeutend, sehen aber textuell völlig unterschiedlich aus.
Embeddings lösen dieses Problem. Textabschnitte werden in hochdimensionale mathematische Vektoren umgewandelt. Ähnliche Inhalte liegen im Vektorraum nah beieinander, unabhängig vom genauen Wortlaut. Das System erkennt dadurch semantische Ähnlichkeiten und identifiziert gezielt abweichende Klauseln.
Halluzinationen kontrollieren: Vertrauen mit Grenzen
Ein bekanntes Problem von LLMs sind Halluzinationen. Das Modell produziert Aussagen, die plausibel klingen, aber faktisch falsch sind. Im Vertragskontext sind solche Fehler besonders kritisch. Eine falsch zusammengefasste Gewährleistungsklausel oder eine übersehene Haftungsausnahme kann erhebliche finanzielle Konsequenzen haben.
Professionelle Systeme begegnen diesem Risiko mit mehreren Maßnahmen. Die wichtigste ist Transparenz: Jede Aussage der KI wird mit der exakten Originalpassage aus dem RAG-Prozess belegt, aus der sie abgeleitet wurde. Nutzer*innen können per Klick zur Quelle springen und die Aussage manuell überprüfen.
Ergänzend kommen weitere Maßnahmen zum Einsatz. Durch Prompt Engineering wird das Modell explizit angewiesen, nur zu antworten, wenn es sich sicher ist, Beispielantworten vorzugeben und offen zuzugeben, wenn es etwas nicht weiß. Fine-Tuning bezeichnet das Weitertrainieren eines vortrainierten Modells auf einem spezialisierten Datensatz, etwa juristischen Fachtexten, Musterverträgen oder kommentierten Entscheidungen um die Qualität für den konkreten Anwendungsfall zu verbessern. Guardrails fügen eine zusätzliche Sicherheitsschicht hinzu: Ein nachgeschalteter Agent überprüft die Antworten, automatisierte Tools erkennen typische Halluzinationsmuster, und Faktenprüfungen stellen die Konsistenz mit den Quelldokumenten sicher. Fortgeschrittene Systeme nutzen zudem Multi-Step-Reasoning, bei dem das Modell schrittweise vorgeht, anstatt direkt eine Antwort zu generieren.
Trotz aller Maßnahmen kann die KI juristische Fachexpertise nicht ersetzen. Sie reduziert den manuellen Aufwand und gibt Rechtsteams mehr Zeit für die wirklich wichtigen Entscheidungen.
On-Premises statt Cloud: Kontrolle über die Infrastruktur ist entscheidend
Verträge enthalten sensible Geschäftsinformationen – Preiskonditionen, Liefermengen, Exklusivvereinbarungen. Die Übertragung solcher Dokumente an externe Cloud-Dienste bedeutet einen Kontrollverlust über kritische Unternehmensdaten. Für viele Unternehmen ist das keine akzeptable Option.
Der Betrieb eines LLMs auf eigenen Ressourcen (On-Premises) löst dieses Problem. Die Daten verlassen das Unternehmensnetzwerk nicht. Es gibt keine Abhängigkeit von externen Diensten, keine unklaren Vertragsbedingungen zur Datenweitergabe und keine Fragen zur Nutzung von Eingabedaten für Modelltraining.
Die technische Basis dafür liefern leistungsfähige Open-Source-Modelle. Modelle wie Mistral, Qwen und Gemma lassen sich vollständig auf eigenen Ressourcen betreiben. Geeignete Systeme sind mittlerweile ab ca. 5000 EUR erhältlich, wobei bei dieser Preisklasse Abschläge bei Laufzeit und Durchsatz bei paralleler Nutzung hingenommen werden müssen. Ab ca. 50.000 EUR stehen Lösungen zur Verfügung, die genug Ressourcen für die meisten Anforderungen von KMUs zur Verfügung stellt.
Durch Integration unternehmensspezifischer Vertragsdaten lassen sich diese Modelle in ihrer Qualität deutlich verbessern und auf den konkreten Anwendungsfall optimieren. Ein On-Premises-Betrieb ermöglicht zudem volle Kontrolle über Modellversionen, Updates werden erst nach interner Prüfung und Freigabe eingespielt.
Integration in bestehende Systeme: Der nächste Schritt zur unternehmensweiten Lösung
Die technische Kernfunktion eines LLMs, welches Verträge liest, bewertet und vergleicht lässt sich als eigenständiges Produkt bereitstellen und einkaufen. Der anschließende Schritt besteht in der strukturierten Ausrollung dieses Vertrags-LLM in die bestehende Unternehmensinfrastruktur.
Viele Unternehmen nutzen bereits Vertragsmanagement-Systeme. Eine KI-Lösung, die als Insellösung neben diesen Systemen läuft, schafft Medienbrüche und wird im Alltag kaum genutzt. Entscheidend ist deshalb die nahtlose Einbindung über standardisierte Schnittstellen. Bei einem On-Premises-Betrieb liegt die Kontrolle über diese Schnittstelle vollständig beim Unternehmen. Anpassungen, Erweiterungen und Sicherheitsupdates können ohne externe Abstimmung umgesetzt werden.
Ein durchdachtes Rollen- und Rechtekonzept ist weiters essentiell. Nicht jede*r Mitarbeiter*in soll alle Verträge einsehen können. Die KI-Lösung muss bestehende Zugriffsrechte respektieren und in das Identity-Management des Unternehmens integriert sein – auch das ist On-Premises einfacher und sicherer umzusetzen als in einer geteilten Cloud-Umgebung.
Fazit
KI-gestützte Vertragsanalyse ist heute produktionsreif. LLMs, kombiniert mit RAG, domain-spezifischen Embeddingmodellen und kontrollierter Ausgabe, lösen die zentralen Herausforderungen: lange Dokumente, semantischer Vergleich und Nachvollziehbarkeit.
Wer dabei auf einen On-Premises-Betrieb setzt, gewinnt mehr als Datenschutz volle Kontrolle über Modelle, Daten und Infrastruktur. Außerdem wird damit eine Basis geschaffen, die sich an veränderte Anforderungen anpassen lässt, ohne Abhängigkeit von externen. Unternehmen, die diese Grundlagen heute legen, schaffen somit eine skalierbare und nachhaltige Lösung, die exakt die eigenen Anforderungen zugeschnitten sind.