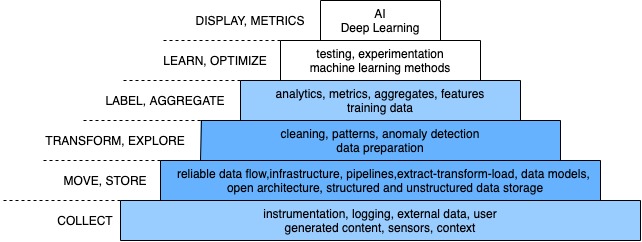
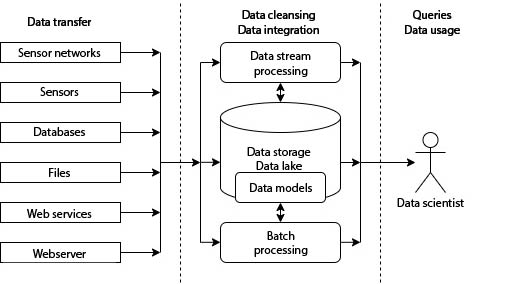
Data storage and data modeling for Big Data
The cleaned and integrated data can be stored in a suitable data storage solution. In the application area of Industry 4.0, for example, data is generated continuously by sensors, which often leads to data volumes in the terabyte range within months. Such data volumes are often no longer manageable with a classic relational database. Although there are scalable databases available on the market that use the relational model, these are not an option for many implementation projects – especially in the SME sector – due to their high licensing costs.
As an alternative, horizontally scalable NoSQL systems are available, the term being an abbreviation for “Not only SQL“. This term covers data stores that use non-relational data models. The property of horizontal scalability refers to the possibility of expanding such systems by integrating additional hardware for basically unlimited data volumes. Typical representatives of NoSQL systems are also often subject to liberal licensing models such as the Apache license and can thus also be used commercially without license costs. In addition, these systems do not place any special requirements on the hardware used, which further reduces the acquisition costs of such systems. Thus, NoSQL systems such as Apache Hadoop and related technologies represent a cost-effective way of executing queries on data volumes in the terabyte range.
Particularly in the Big Data area, the selection of a suitable NoSQL database and a suitable data model is of central importance because both aspects are central to the performance of the overall system. This refers both to the input of data and to queries against the NoSQL system.
The selection of the technology to be used as well as the data model design is clearly driven by the system requirements:
- What data volumes and data rates need to be imported?
- Which queries and evaluations are to be performed with the data?
- What are the performance requirements for the queries? Is it a real-time system?
The central question is, for example, whether the system should only support fixed queries or – for example, using SQL – allow flexible queries.
In the context of technology selection, a distinction can be made, for example, as to whether data is always accessed via a known key or whether queries are also made on the values of other attributes. In the first case, a system with the semantics of a distributed hash map, such as Apache HBase, is suitable, while in the other case, for example, an in-memory analysis solution such as Apache Spark is suitable. If the use of the data is primarily aimed at the links between data, the use of a graph database should be considered.
In a Big Data system, data is stored denormalized for performance reasons, i.e., all data relevant to a query result should be stored together. The reason for this is that performing joins is very resource-intensive and time-consuming. Therefore, the planned queries are central to the design of the data model. For example, the attributes that mainly appear as parameters in the queries should be used as key attributes. This is also the reason why the data model often has to be extended when new queries are added to ensure their effective execution, and thus data engineering activities are continuously required even after the data has been introduced.
With its expertise in the field of open source NoSQL databases built up over more than ten years, RISC Software GmbH represents a reliable consulting and implementation partner for the introduction or expansion of a solid database in your company, regardless of the area of application.