Data quality: From information flow to information content
Why clean data (quality) management pays off
by Sandra Wartner, MSc
Making decisions is not always easy – especially when they are relevant to the fundamental direction of the company and can therefore have an impact on a far-reaching corporate structure. This makes it all the more important to know as many influencing factors as possible in the decision-making process, to quantify facts and to incorporate them directly (instead of making assumptions) in order to minimize potential risks and achieve continuous improvements in the corporate strategy. A potential quick win for companies can be derived from corporate data: future-oriented data quality management – a process that unfortunately often receives far too little attention. Here we explain why the existence of large data streams is usually not enough, what decisive role the condition of the stored data plays in data analysis and decision making, how to recognize good data quality and why this can also be important for your company.
Contents
What does bad data cost?
Data basis and data quality – what’s behind it?
How do you recognize poor data quality and how can these data deficiencies arise in the first place?
Data as fuel for machine learning models
Data quality as a success factor
Sources
Author
What does bad data cost?
When shopping in the supermarket, we look for the organic seal of approval and regional products, when buying new clothes, the material should be made from renewable raw materials and under no circumstances produced by child labor, and the electricity provider is selected according to criteria such as cleanliness and transparency – because we know what impact our decisions can have. So why not stick to the principle of quality over quantity when it comes to data storage and data management?
In the age of big data, floods of information are generated every second, which often serve as the basis for business decisions.According to a study by MIT1 , making the wrong decisions can cost up to 25% of sales. In addition to the financial loss, an unnecessarily high use of resources or additional effort is required to rectify the resulting errors and correct the data, and the proportion of satisfied customers and trust in the value of the data decreases. Google is not the only company to have had to deal with the drastic consequences of errors in its data, including with its Google Maps2 product. Address details at the wrong location even led to a demolition company accidentally razing the wrong house to the ground; incorrectly lower mileage to the navigation destination via non-existent roads left drivers stranded in the desert or landmarks suddenly appeared in the wrong places. NASA also had to watch on September 23, 1999 as the Mars Climate Orbiter and more than $120 million burned up on its approach to Mars – the reason: a unit error3. Even if the effects of poor data quality are not quite as far-reaching as those of the big players, the issue of data quality still affects every company.
From a business perspective, data quality is not an IT problem, but a business problem. This usually results from the fact that business professionals are not or not sufficiently aware of the importance of data quality and that data quality management is successively weak or lacking altogether. Linking data quality practices with business requirements helps to identify and eliminate the causes of quality deficits, thereby reducing the error rate and costs and ultimately enabling better decisions to be made.
Figure 1: From data quality to sustainable decisions and products
Despite the criteria mentioned above, it is not easy to describe good or poor data quality on the basis of more specific characteristics, as data exists in a wide variety of structures that differ greatly in their properties. The data collected in the company is made up of different data depending on the degree of structuring:
Structured data is information that follows a predefined format or structure (usually prepared in tabular form) and may even be sorted systematically. This makes it particularly suitable for search queries for specific pieces of information such as a specific date, zip code or name.
Unstructured data, on the other hand, is available in a non-normalized, unidentifiable data structure and therefore makes processing and analysis more difficult. This includes, for example, images, audio files, videos or text.
Semi-structured data follows a basic structure that contains both structured and unstructured data. A classic example of this is emails, for which the sender, recipient and subject must be specified in the message header, but the content of the message consists of arbitrary, unstructured text.
Data basis and data quality – what’s behind it?
There are already many definitions of the term data quality, but a general statement can only be made to a limited extent, as good data quality is usually defined on a domain-specific basis. A large data set alone (quantity) is no indication that the data is valuable. The decisive factor for the actual usefulness of the data in the company is above all whether it correctly reflects reality (quality) and whether the data is suitable for the intended use case.
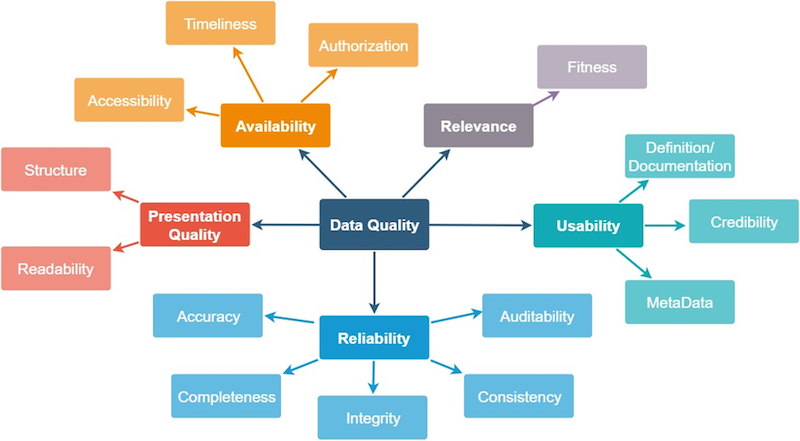
There are various general approaches and guidelines for assessing the quality of data. Good data quality is often understood very narrowly as the correctness of content, which means that other important aspects such as trustworthiness, availability or usability are ignored. Cai and Zhu (2015)4, for example, define the data quality criteria shown in Figure 2 as availability, relevance, usability, reliability and presentation quality. In the following, some relevant points for the implementation of data-driven projects are discussed on the basis of these criteria.
Figure 2: Data quality criteria according to Cai and Zhu (2015)
Relevance: In data analysis projects, it is particularly important at the outset to consciously consider whether the data on which the project is to be based is suitable for the desired use case. In AI projects, it is therefore always important to be able to answer the following question with “yes”: Is the information needed to answer the question even available in its entirety in the data? If even domain experts cannot identify this information in the data, how is an AI supposed to learn the correlations? After all, machine learning algorithms only work with the data provided to them and cannot generate or utilize any information that is not contained in the data.
Usability: Metadata is often needed in order to interpret data correctly and therefore be able to use it at all. Examples of this include coding, origin or timestamps. The origin can also provide information about the credibility of the data, for example. Depending on the content of the data, good documentation is also important – if codes are used, for example, it may be important to know what they stand for, or additional information may be required in order to be able to read date values, timestamps or similar correctly.
Reliability: Probably the most important aspect when evaluating data and its quality is how correct and reliable it is. The decisive factor here is whether the data is comprehensible, whether it is complete and whether there are contradictions in it – quite simply, whether the information it contains is correct. If you already have the feeling that you don’t trust your own data and its accuracy, you won’t trust analysis results or AI models trained on it either. In this context, accuracy is often a decisive factor: for one question, roughly rounded values may be sufficient, while in another case, accuracy to several decimal places is essential.
Presentation quality: Logically, data must not only be able to be “processed” by computers, but above all by humans. In many cases, it must therefore be well-structured or prepared so that it can be read and understood by humans.
Availability: At the latest when you want to actively use certain amounts of data and integrate them into an (AI) system, for example, it must also be clarified who is allowed to access this data and when, and how this access is (technically) enabled. Logically, timeliness is also crucial, especially for real-time systems. After all, if you want to process data in real time (e.g. to monitor production facilities), access to it must be fast and reliable.
How do you recognize poor data quality and how can these data deficiencies arise in the first place?
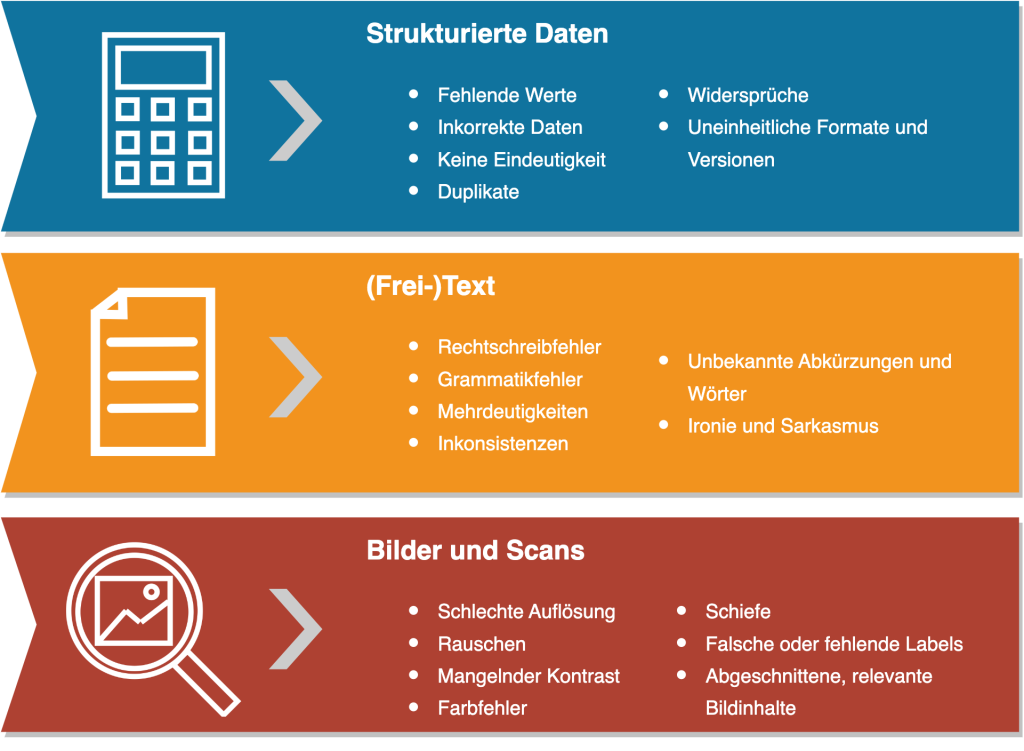
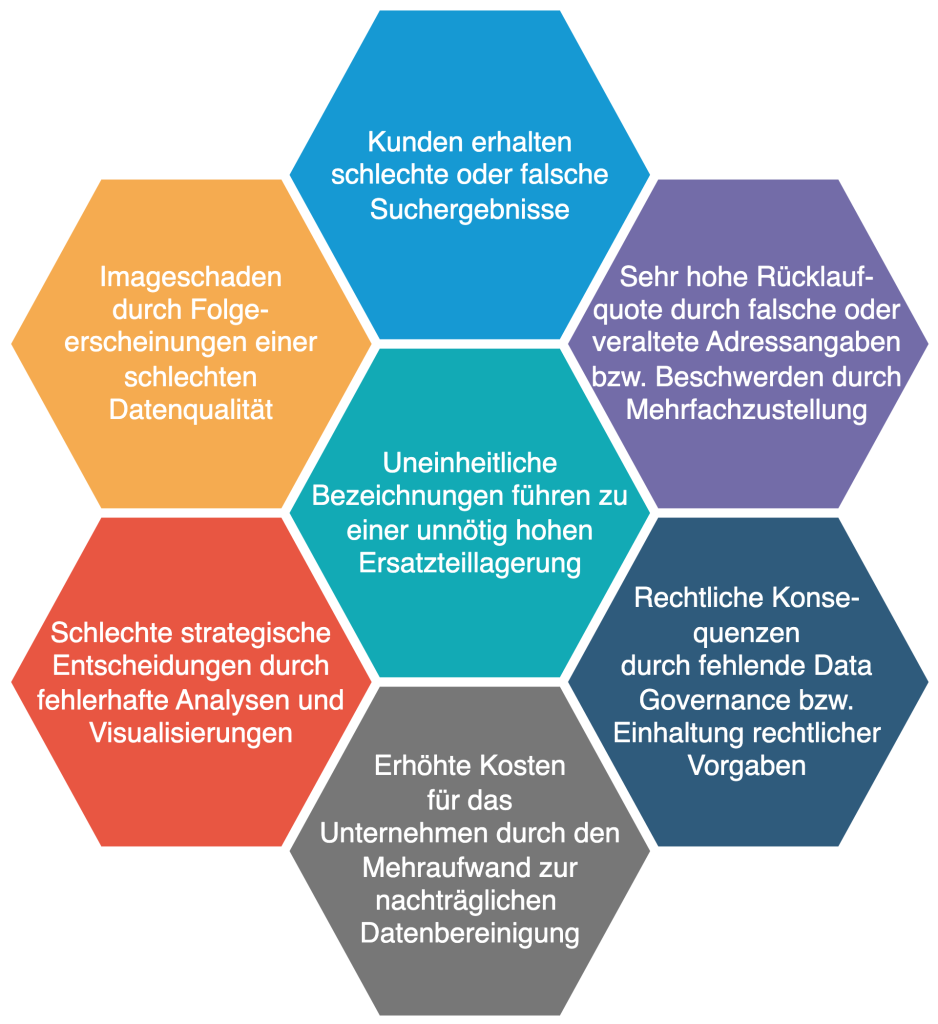
Poor data quality is usually not as inconspicuous as you might think. On closer inspection, a wide variety of deficiencies quickly become apparent, depending on the degree to which the data is structured. Let’s be honest – are you already familiar with some of the cases shown in Figure 3? If not, take the opportunity to search for these conflict generators, as you are very likely to find some of them. This data can take many forms in practical application and manifest itself in various problems such as damage to image or legal consequences (Figure 4 shows just a few of the negative effects). The costs of poor data quality can also be far-reaching, as we have already made clear in “What does bad data cost”. But how can such problems arise in the first place?
Figure 3: Examples of poor data quality according to the degree of data structure
Figure 4: Negative examples from practice
The fundamental causes often lie in the lack of responsibility for data management or the lack of data quality management in general, but technical challenges can also cause problems. These errors often creep in over time. Different data collection processes and the merging of data from different systems or databases are particularly prone to errors. Human input also produces errors (e.g. typing errors, confusion of input fields). A further problem lies in data ageing: problems arise in particular when changes are made to data collection or recording (e.g. missing sensor data during machine changeover, lack of accuracy, sampling rate too small/too large, lack of know-how, changing requirements for the database). Further risk factors are the (often missing) documentation and the (consequently incorrect) versioning of the data.
In practice, perfect data quality is usually a utopian idea that is also influenced by many factors that are difficult or impossible to control. However, this shouldn’t deprive anyone of hope, because: In most cases, even small measures can have a big impact.
Data as fuel for machine learning models
It is not only in traditional data analysis that special attention should be paid to the data in order to obtain the maximum significance of the results. Especially in the field of artificial intelligence (AI), the available database plays a decisive role and can help a project to a successful conclusion or condemn it to failure. By using AI – specifically machine learning (ML) models – frequently repetitive processes can be intelligently automated. Examples include searching for similar data, deriving patterns or recognizing outliers or anomalies. It is also essential to have a good understanding of the data (domain expertise) in order to identify potential influencing factors and be able to control them, and well-known principles such as “decisions are no better than the data on which they’re based” and the classic GIGO idea (garbage in, garbage out) clearly underline how essential the necessary database is for the learning process of ML models. Only if the database is representative and depicts reality as accurately as possible can the model learn to generalize and successively make the right decisions.
Data quality as a success factor
Data quality should definitely be the top priority for data-based work. Furthermore, awareness of the relevance of good data quality should be created or sharpened in order to achieve positive effects throughout the company, reduce costs and use freed-up resources more efficiently for the really important activities. Our conclusion: good data quality management saves more than it costs, enables the use of new methods and technologies and helps to make sustainable decisions.