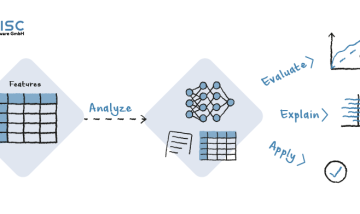
Analyze and validate data automatically and use it to train machine learning models
CaTabRa is a versatile platform for the secure, local analysis and visualization of data. It was developed to support a wide range of industries in the efficient use and evaluation of their data.
Today, companies and private individuals collect data in almost all areas of life – when shopping online, in fitness apps or in production processes. This information is usually used to make automatic predictions. Typical questions are, for example:
Which target groups should my product be suggested to?
What weight loss can I expect if I run one lap a day?
When do I need to replace wearing parts to reduce downtimes?
Complex analyses and technical expertise are required to make such predictions possible. However, not every project can afford this effort.
This is where CaTabRa comes in. The platform is an open source tool that automates steps in the analysis of tabular data and supports prediction models. This benefits both domain experts without in-depth technical knowledge and data scientists who want to work more efficiently with data.
With CaTabRa, statistical evaluations, the training of machine learning models, the explanation of model decisions and the validation of input data are done with little effort.
Advantages of using CaTabRa
Users quickly gain insights and can immediately decide whether the use of machine learning is worthwhile.
The generated diagrams can be used in publications without any post-processing.
In contrast to cloud solutions, sensitive data remains protected because everything happens locally.
Users can easily expand CaTabRa with their own methods. At the same time, many out-of-the-box configurations are available.
Developers can also use the features directly in the code via programming interfaces, including methods for data preparation.