Das Feld der natürlichen Sprachverarbeitung (Natural Language Processing, kurz NLP) beschäftigt sich mit dem Verständnis natürlicher menschlicher Sprache. Einen Einstieg in das Thema bietet der Fachartikel OK Google: Was ist Natural Language Processing?.
Da zum maschinellen Aufbau von Verständnis für natürliche Sprache überaus große Mengen an Textdaten von mehreren Gigabyte nötig sind (bspw. der gesamte Text aus Wikipedia), ist das Training von NLP-Systemen von Grund auf mit erheblichen Kosten (bis zu sechsstelligen Euro-Beträgen oder mehr) und Zeitaufwand verbunden[1], bis eine akzeptable Qualität der Ergebnisse erreicht werden kann. Deswegen stellen zahlreiche Forscher*innen sowie auch Großunternehmen wie Google oder Facebook vortrainierte Sprachmodelle öffentlich zur Verfügung. Da diese sogenannten Basismodelle bereits ein grundlegendes Verständnis für Sprache erlernt haben, können andere Forscher*innen auf diesen Modellen aufbauen und sie für ein konkretes Vorhaben anpassen, erweitern und wiederum mit der NLP-Community teilen.
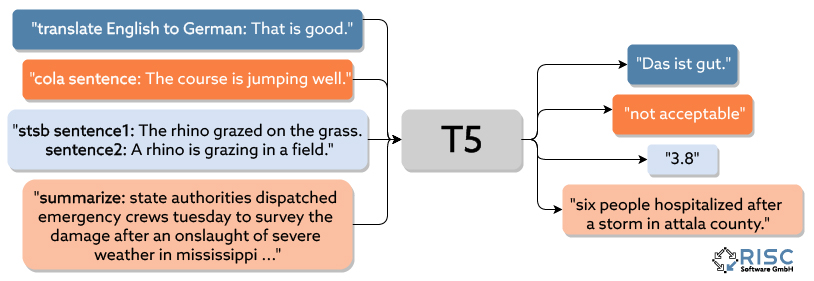
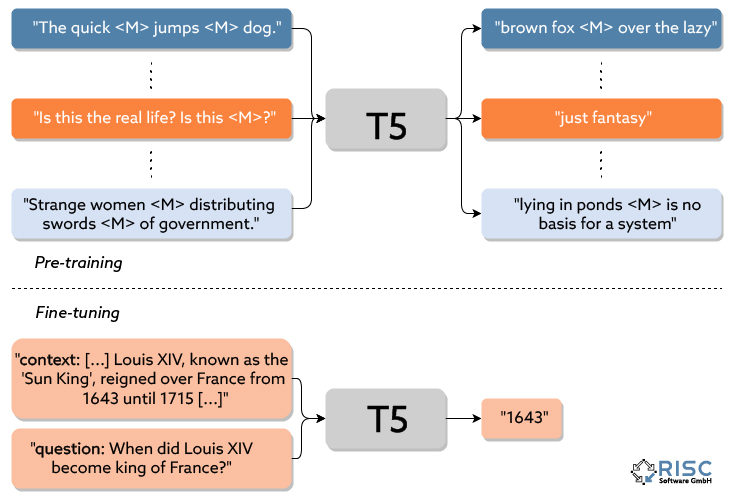
Dieses Konzept wird als Transfer-Learning bezeichnet. Hierbei werden Modelle mit riesigen Datenmengen darauf trainiert, ein allgemeines Verständnis für grundlegende Konzepte (in diesem Fall natürlicher Sprache) zu erlangen, und anschließend mit spezielleren Daten darauf trainiert, eine konkrete Aufgabe zu erledigen. Dies erlaubt nicht nur die Wiederverwendung von Modellen, sondern verringert auch die Größe der für eine konkrete Aufgabe benötigten Datenbasis.
Wenn nur wenige Daten zur Verfügung stehen, kann man auf Zero-Shot-Learning zurückgreifen. Hierbei wird ein Modell dazu gebracht, eine Aufgabe zu erfüllen, auf welche es nicht explizit trainiert wurde. Nach diesem Prinzip arbeiten auch One-Shot und Few-Shot Modelle. Somit können Modelle mit keinen oder nur wenigen Daten auf eine bestimmte Aufgabe getrimmt werden. Leider ersparen diese Ansätze das Sammeln von Trainingsdaten in sehr vielen Fällen nicht völlig: erstens dienen diese Zero-Shot-Modelle oftmals nur als Prototypen bzw. Baseline-Modelle, da diese häufig nicht ausreichend gut generalisieren können (d.h. sinkende Qualität der Ergebnisse bei neuen, ungesehenen Daten) und sehr anfällig für Fehler in den (Trainings-)Daten sind. Zweitens sind zusätzlich Evaluierungsdaten nötig, um die Qualität der Zero-Shot-Modelle überhaupt erst quantifizieren zu können und eine Einschätzung für den durch ihren Einsatz erzielten Mehrwert getroffen werden kann.
Einen der größten Durchbrüche der letzten Jahre im NLP-Bereich stellt die Entwicklung sogenannter Transformer-Modelle dar. Hierbei handelt es sich um eine besondere Architektur von neuronalen Netzen, welche sogenannte Attention-Mechanismen verwendet und die zuvor vorherrschenden rekurrenten neuronalen Netze (RNN) durch tiefe Feed-Forward-Netze ersetzt. Diese neuartige, 2017 entwickelte Architektur konnte die Schwächen der Vorgängermodelle weitgehend ausmerzen. Sie ermöglicht u.a. ein (besseres) Verständnis über den Kontext bestimmter Wörter und erleichtert den performanten Umgang mit größeren Datenmengen. Das wohl bekannteste Beispiel einer Gruppe von Transformer-Modellen stellt BERT[2] (Bidirectional Encoder Representations from Transformers) dar. Die grundlegenden BERT-Modelle können um maßgeschneiderte Erweiterungen ergänzt werden, welche auf die gewollte Aufgabe (z.B. Klassifizierung von Sätzen auf negative, neutrale oder positive Stimmung) trainiert werden. Auf der BERT-Architektur basierende Systeme konnten seit der Publikation in 2018 in zahlreichen Aufgaben rekordbrechende Ergebnisse erzielen und sind mittlerweile fester Bestandteil der Google-Suche.