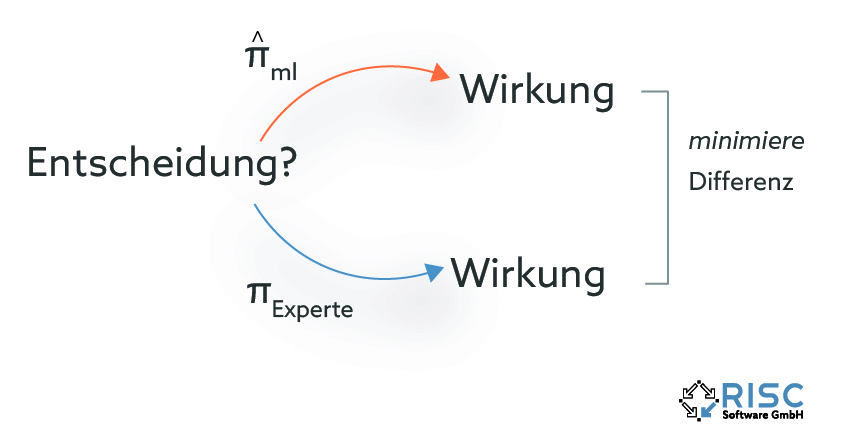
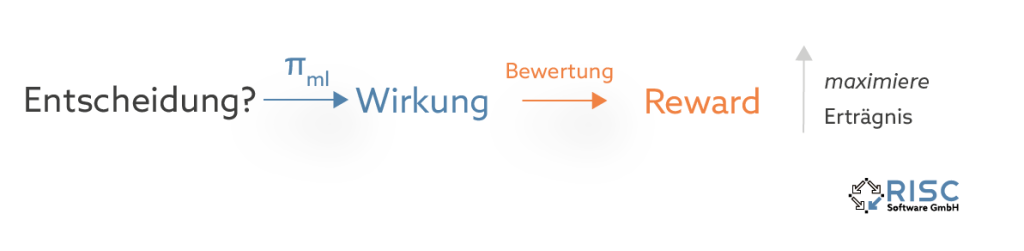
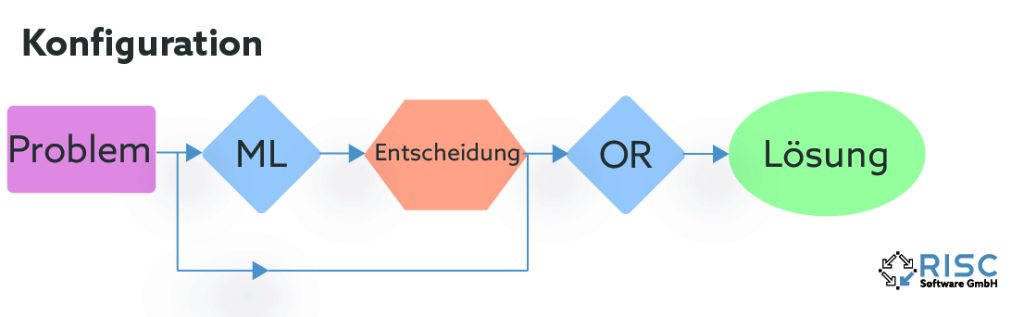
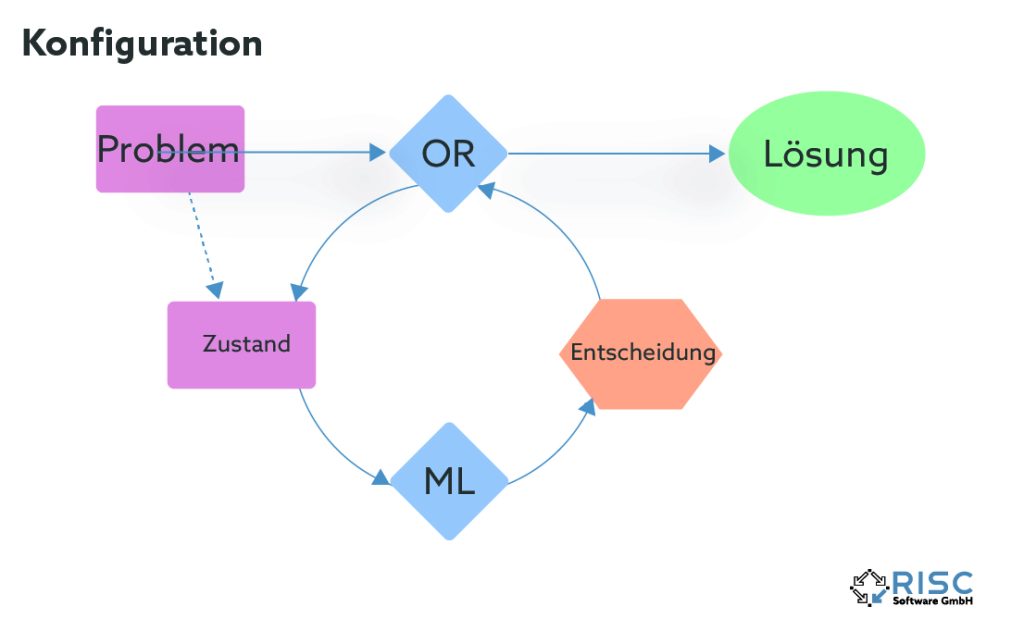
What is learned?
After the question of how learning takes place has been clarified, the much more important question remains unanswered: What exactly is learned? There are different approaches to this question, depending on the properties of the properties of the optimization method used and problem-specific factors.
- Parameter tuning through ML
Metaheuristics usually contain a number of parameters that have a significant impact on performance. Machine learning can be used to learn these parameters for a specific class of problem or for individual instances of a problem. Techniques of linear or logistic regression, neural networks or response surface methods are particularly used.
- Target function evaluation by ML
For complex problems, evaluating the objective function requires a lot of computational effort. Machine learning can be used to create an approximation of the objective function and thus speed up the evaluation. Polynomial regression, neural networks or Markov fitness models are popular ML methods that can be used for this purpose.
- Population and operator management through ML
Many metaheuristics (such as local search methods) use operators to generate new promising solutions starting from already generated solutions. In genetic algorithms, we also talk about populations that are modified by mutation and crossover operators. Often, the use of these operators is prescribed in advance by fixed rules based on the solution properties. However, these rules can also be continuously adapted and improved by machine learning. For example, inverse neural networks or classification algorithms from the field of symobolic learning methods are suitable for learning rules that do not repeat previous failed attempts and can explain why some operators are more suitable than others at this point.
- Algorithm selection by ML
It may happen that a whole portfolio of different solution methods is available for the same problem class and one is interested in which of them provides the best performance. The algorithm selection problem describes exactly this situation, in which a solution method a is to be selected from the set of available methods A in such a way that the performance of a, applied to a problem x, is best possible among all methods in A. This selection problem is to be solved depending on the problem properties of the problem x. This selection problem is to be solved depending on the problem properties of problem x. Classification algorithms and neural networks are suitable to divide the available portfolio A into more or less promising methods based on the problem properties.
- Determination of the execution order by ML
The branch-and-bound framework is a widely used exact solution method. The problem is broken down piece by piece into smaller subproblems (“branching“) and can be represented in a tree structure (“branch and bound tree“ / “search tree“), in which each node represents an incomplete solution of the overall problem. Lower bounds can then be computed for these nodes by relaxing the restrictions. At the same time, upper bounds can be found by heuristically solving the subproblems, and as soon as the lower bound is above the upper bound for a node in the search tree, the entire “branch“ can be discarded, which in turn restricts the search space (“bounding“). The faster good upper bounds are found, the faster entire regions of the search space can be discarded, resulting in a significant performance improvement of the branch-and-bound algorithm. To obtain such upper bounds, various heuristics are used that attempt to generate an admissible good solution in each node. However, it is highly dependent on the particular problem and instance which existing heuristic yields the best results. It would be desirable to use the best heuristic in each case early and not waste time with worse heuristics beforehand. Typically, the execution order of heuristics is defined in advance, independent of the particular problem instance and incapable of responding to dynamic changes during the search run. A new approach improves the execution order of heuristics in a data-based manner and continuously adjusts it during the search run.