Methods and tools for data preparation in the big data area
by DI Paul Heinzlreiter
In recent years, the role of big data in numerous economic sectors such as the manufacturing industry, logistics or trade has become increasingly important. Using a wide variety of sensor systems, large amounts of data are collected that can subsequently be used to optimize machines or business processes. Methods from the fields of artificial intelligence, machine learning or statistics are often used here.
However, all these methods require a larger quantity of high-quality and valid data as a basis. In this context, data engineering is used to collect the raw data, cleanse it and merge it into an integrated database. While a previous article (the magazine INSIGHT #1) highlighted the general role and goals of data engineering, this article will focus on methods and proven tools as well as provide an exemplary insight into the algorithmic implementation of data engineering tasks.
Table of contents
Data stream and batch processing
Data stream processing: Apache NiFi
Batch processing: Apache Hadoop
Hadoop File System (HDFS)
Map-Reduce-Framework (YARN)
Batch and data stream processing: Apache Spark
Application example: Processing of industrial sensor and log data
Application example: Cleaning sensor data and storing it in an SQL database
Choosing the right tools for big data engineering
Sources
Author
Data stream and batch processing
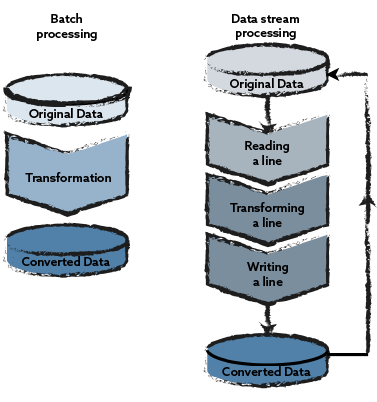
If, for example, industrial sensor data is collected over time, large amounts of data do not accumulate per unit of time (e.g. every few seconds), but over months and years the stored data volumes often increase into the terabyte range. If data in this order of magnitude is to be processed, this can essentially be done using two different paradigms, described here for converting the data type of a table column:
Batch Processing: Here, all rows in a table are processed in parallel to convert one column.
Data stream processing (Data Streaming): Here, the rows of the table are read sequentially and the column conversion is performed per row.
The main difference between the two data processing approaches is that in data streaming, the necessary data transformations – such as converting data fields to other data types – are performed directly on the currently supplied data set, whereas in batch processing, the data is first collected, and subsequently the data transformations are performed on the entirety of the data.
Which approach is chosen depends on the data transformation requirements:
If the transformation can be performed locally on the currently queried or received data, the use of the data streaming approach is often preferable, since it is usually a simple and local operation that can also be processed more quickly due to the smaller input data. A typical application of Data Streaming is the direct conversion of sensor data arriving distributed over time, as these can then be converted and stored individually.
However, if the data transformation requires input data from the entire data already stored or if all data is already available, a batch approach is more suitable. Parallel processing of the data is also often easier to implement here, as this is directly supported by frameworks such as Apache Hadoop (through the Map-Reduce approach) or Apache Spark.
In general, the data obtained should be stored once in raw format in order to not lose any data that could still be needed as a basis for future analyses. Further processing of data stored in this way can then be done by batch processing or data streaming. In the second case, a data stream is generated again from the stored data by continuous reading. Conversely, a data stream can be stored continuously and thus serve as a starting point for batch processing.
Data stream processing: Apache NiFi
NiFi represents a tool for data stream processing, which makes it possible to connect data transformations in a graphical, web-based user interface to form a continuous data pipeline through which the source data flows and is transformed step by step. The strengths of Apache NiFi lie in the wide range of modules already available, which enable, for example, the reading and storing of numerous data formats. Due to the open source character of NiFi and the object-oriented structure of its modules, it is easy to develop your own modules and integrate them into data pipelines. Furthermore, NiFi also addresses issues such as the automated handling of different processing speeds of the modules.
Batch processing: Apache Hadoop
Hadoop is a software framework based on the fundamental principle of parallel data processing in a cluster environment. Within the distributed processing, each cluster computer takes over the processing of the data locally available there, which above all saves communication effort during the calculations. Hadoop distinguishes here between controller and responder services in the cluster, whereby the responder services take over the processing of the locally available data, while the controller services are responsible for the coordination of the cluster. Parts of the algorithms implemented in Hadoop were developed by Google and the concepts published in research papers, such as the Google File System, Map-Reduce and Google Bigtable. At Google, these solutions are used to operate the global search infrastructure, while the Hadoop project is an open-source implementation of these concepts.
At its core, a Hadoop system consists of a usually Linux-based cluster running the Hadoop File System (HDFS) and YARN as an implementation of the Map-Reduce algorithm. A Hadoop cluster with the HDFS and YARN services provides a solid technological basis for a wide variety of Big Data services such as BigTable databases like HBase – see below – or graph databases like JanusGraph, for example.
Hadoop File System (HDFS)
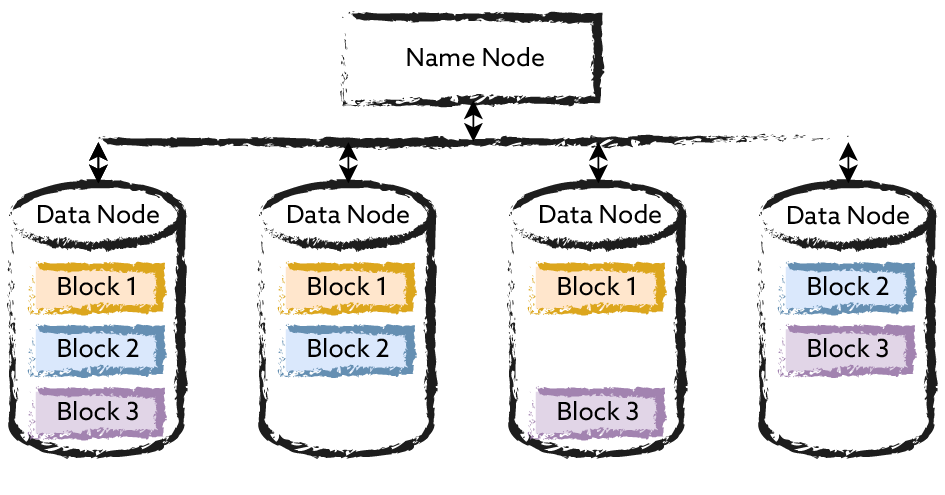
HDFS is an open source implementation of the Google Filesystem. Like other Hadoop subsystems, it consists of controller and responder components, in the case of HDFS Namenodes (controllers) and Datanodes (responders). While a Namenode stores where on the cluster the data for individual files is stored, the Datanodes handle the storage of the data blocks. Basically, HDFS is optimized for large files, the block size for storage is usually 128 megabytes. On the one hand, a file can consist of many individual blocks, on the other hand, the data blocks are replicated across multiple cluster nodes for redundancy and performance reasons. The access semantics of HDFS are different from the usual Posix semantics, since only data can be appended to HDFS files, but they cannot be edited. To create a new version of a file, it must be replaced. This can be done very effectively even for large files using the Map-Reduce algorithm described below.
In the context of a Hadoop system, text files stored in CSV format, for example, can now be processed with Map-Reduce jobs, with the distribution of sub-jobs across the cluster based on the distribution of the HDFS file blocks being handled automatically by the Hadoop framework. In addition to plain text files, structured binary data such as ORC, Parquet or AVRO formats can also be processed directly by Hadoop. In addition, specific splitter classes for Map-Reduce can be implemented for new formats.
Furthermore, as part of a Map-Reduce algorithm, it is possible without problems to perform only one map stage, for example, to add new columns to a CSV file.
Map-Reduce Framework (YARN)
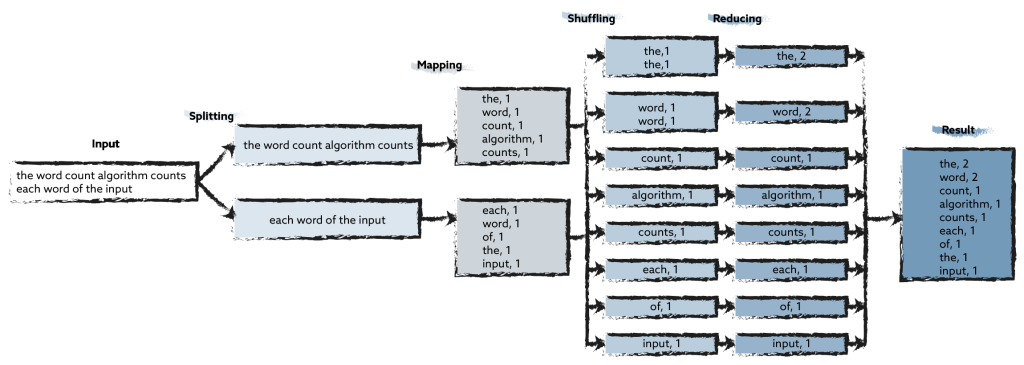
Based on the data distribution in HDFS shown above, a data-parallel batch job can now be executed by the YARN service, with each responder node processing the locally available data blocks. Conceptually, the execution follows the Map-Reduce algorithm. A classic application example for the Map-Reduce algorithm is the counting of words in text documents. Here, the map step emits a set of pairs of the form (word, number of occurrences in the line) per line. In the Shuffle step, these pairs of values are grouped according to the words, since they represent the key. In the final Reduce step, the word frequencies per word are summed. An exemplary execution could run as follows:
The input text is divided into individual text lines. (Splitting)
The map step, which is executed in parallel for each line individually, creates a pair of the word and the number 1 for each word in the line. (Mapping)
The pairs are sorted by the words and combined into one list per word. (Shuffling)
For each word, the number in the total text is determined by adding up the numbers. (Reducing)
While the Map step and the Reduce step must each be programmed out, the global Shuffle step is automatically taken over by the Map-Reduce framework. In practice, the implementation of the Map and Reduce steps requires, for example, the object-oriented overwriting of one Map and one Reduce method each, whose interfaces are already specified. This allows the focus to be placed on the transformation of a pair of values, while the framework subsequently takes care of the scaled execution on the cluster.
Batch and data stream processing: Apache Spark
Spark is a flexible data processing layer that can be built on top of various infrastructures, such as Hadoop, and can be used for various data engineering and data science tasks. As a general data processing framework, Spark can perform data preprocessing tasks as well as machine learning tasks.
For example, Apache Spark can be installed on an existing Hadoop cluster and directly access the data stored there and process it in parallel. One approach to this is the Map-Reduce algorithm mentioned above, although Spark can also apply other flexible methods such as data filtering. Spark stores intermediate results as resilient distributed datasets (RDDs) in main memory, which avoids slow repetitive disk accesses – as is often the case with classic databases.
Key features of Spark include:
Parallel batch processing, for example using the Map-Reduce algorithm.
Support of SQL queries on arbitrary (e.g. in HDFS) stored data. To do this, you only need to interactively create a table that defines the data schema to be used and references the underlying data.
Based on sequential processing of multiple RDDs, data stream processing can be performed.
Just like an underlying Hadoop cluster, a Spark installation can be made fit for processing larger amounts of data by a simple hardware upgrade.
Application example: Processing of industrial sensor and log data
As part of the VPA4.0 research project, a data pipeline was set up for the pre-processing of production sensor data. This represents a good example of linking streaming and batch processing. Apache NiFi was used as a streaming solution to transmit the data directly from the project partner over the Internet in encrypted form before storing it locally on the Hadoop cluster. Further data processing was then performed using Spark in parallel on the Hadoop cluster and included the following steps:
Unpacking the received data archives and removing unneeded files
Preparation and storage of data as CSV files in HDFS
Creating virtual tables based on CSV files enables further processing with SQL
Data filtering and storage in optimized Parquet format for interactive SQL queries
Application example: Cleaning sensor data and storing it in an SQL database
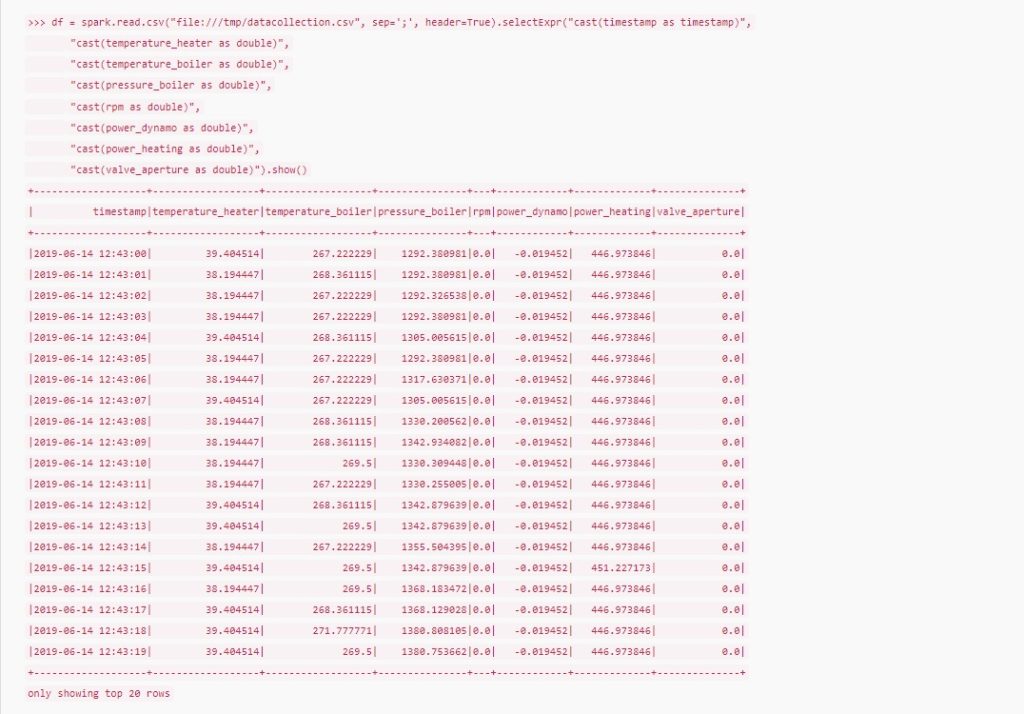
This example includes sensor data collected on a heat engine. In the following example, negative values can be seen in the column power_dynamo, which were caused by a measurement inaccuracy. Rows with such values should now be filtered out as erroneous and the cleaned data stored in a database.
Implementation in Spark:
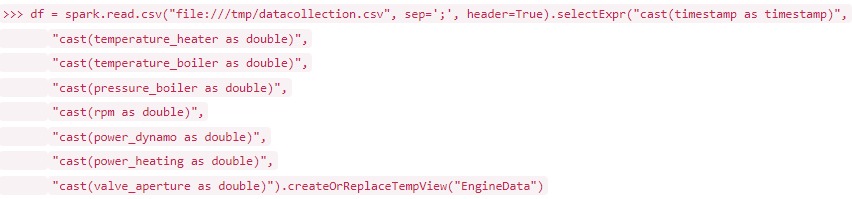
In Spark, the data can be read in as a first step, converted to the correct data types and stored in a correctly typed dataframe. This represents a Spark standard data structure in which data is held in main memory. This can be implemented with a command in an interactive pyspark shell, which uses Python as the implementation language:
With the following command the data can be stored directly in the SQL table EngineData:
To filter out rows with incorrect values, queries can now be used based on the SQL table. In this case negative power_dynamo values are filtered out:
A dataframe can be saved again as a CSV file after cleaning. The inclusion of the repartition function ensures that the result is saved in a file, even if the data frame was previously partitioned. This can be the result of parallel processing steps.
As an alternative, the dataframe can also be stored in a database via the JDBC API. The following command saves the data in a SQLite database, for example:
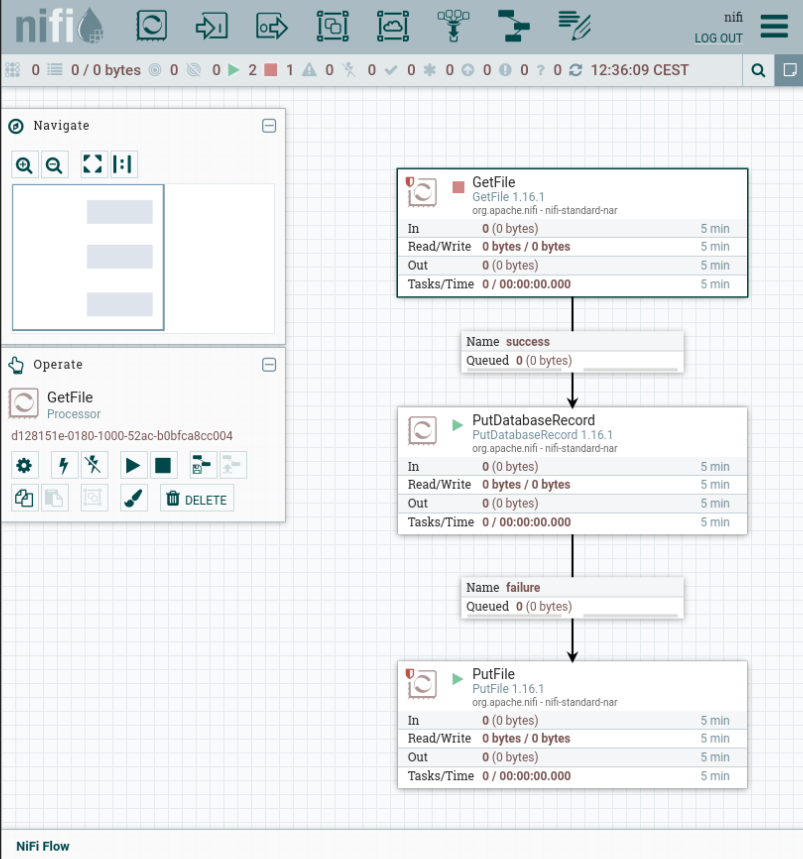
Implementation in NiFi:
The example shown here again shows the reading of the CSV file with the heat engine data and its storage in a SQLite database. Here the CSV file is read in using the GetFile processor and converted into NiFi flowfiles. These are fed into a PutDatabaseRecord processor, which is configured to parse the CSV file correctly and access the database. Just like connecting the individual modules, their configuration is done interactively in the NiFi web interface.
The final PutFile processor is used to catch and store error conditions, such as incorrectly formatted lines in the input file. This allows error conditions to be easily traced in the saved text file.
Choosing the right tools for big data engineering
As can be seen from the application examples shown below (data transfer from a CSV file to an SQL database), different paths often lead to the same goal in the field of data engineering. Which methods should be used often depends on the specific requirements of the customer as well as their system environment:
For example, if a Hadoop cluster is already in use or planned, it can already be integrated when designing a solution.
Public cloud offerings such as Amazon AWS, for example, in turn offer alternatives to the open source solutions described above, which primarily simplify the operation of the solution, but can also lead to vendor lock-in.
Other criteria for a technology decision are requirements for scalability and the planned integration of additional tools.
Last but not least, open source solutions often offer cost advantages, as there are no licensing costs even for highly scalable solutions.
With its expertise in the field of data engineering built up over more than ten years, RISC Software GmbH represents a reliable consulting and implementation partner, regardless of the area of application.
Sources
Bill Chambers, Matei Zaharia: Spark: The Definitive Guide, O’Reilly Media, Inc., February 2018, ISBN: 9781491912218
Tom White: Hadoop: The Definitive Guide, O’Reilly Media, Inc., June 2009, ISBN: 9780596521974
Marz Nathan, Warren James: Big Data. Principles and best practices of scalable realtime data systems, Manning Publications, April 2015, ISBN 9781617290343
Kleppmann Martin: Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems, O’Reilly Media, March 2017, ISBN 9781491903063
V. Naresh Kumar, Prashant Shindgikar: Modern Big Data Processing with Hadoop: Expert techniques for architecting end-to-end Big Data solutions to get valuable insights, Packt Publishing, March 2018, ISBN 978-1787122765