



Working with Fortran in 2020: Areas of application
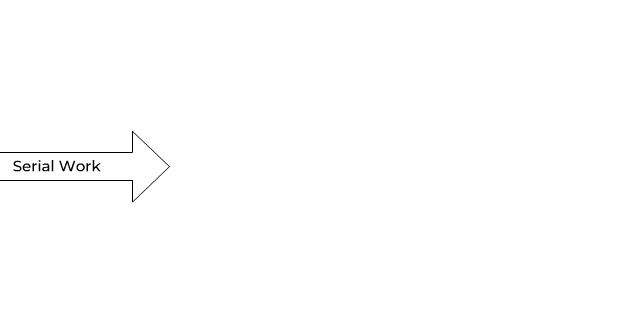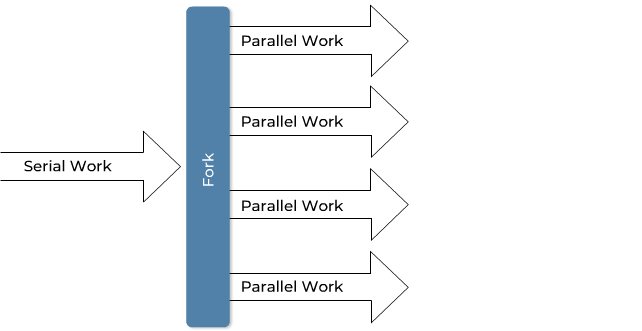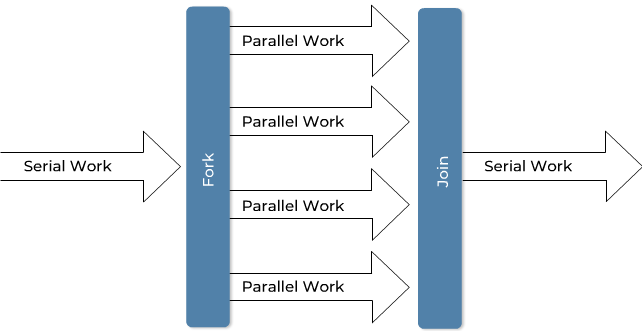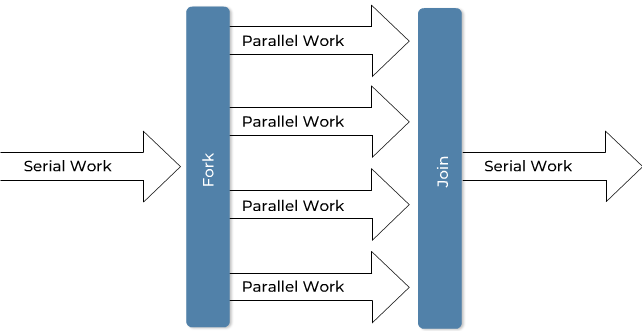
The typical use case for Fortran as a programming language is computationally intensive numerical simulations, such as weather forecasts, flow simulations, stability calculations, and many more.
mehr erfahren