SIGNDETECT project: Automated traffic sign recognition in Upper Austria
Innovative AI project optimizes the recording of traffic signs for road administration
RISC Software GmbH has implemented a project for the automated detection and precise localization of traffic signs together with the Directorate for Road Construction and Transport of the Province of Upper Austria. The partners tested how existing RGB video data from the RoadSTAR recording vehicle can be used for AI-supported detection, classification and localization. Machine learning and stereo camera analyses were used to create a system that reliably recognizes traffic signs and determines their position in real-world coordinates. This significantly improves the management of road databases, which in turn creates a basis for future innovations in traffic monitoring.
Automated and precise localization of traffic signs in road traffic
The state of Upper Austria regularly records road conditions with the RoadSTAR recording vehicle from the Austrian Institute of Technology. In addition to sensor technology, a calibrated stereo camera system is used to document road traffic in RGB videos. RISC Software GmbH examined how these videos can be used for the automatic detection, classification and localization of traffic signs. The system must therefore recognize where a traffic sign is located in the image, what type it is and where it is located in the real world.
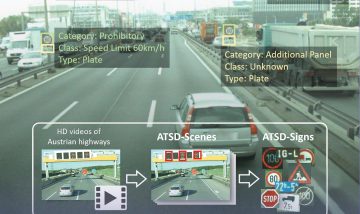
Figure 1: Steps of traffic sign recognition and localization
Creation of a VZ data record
The first step was to reliably record traffic signs. To this end, a representative data set was created for the Austrian road environment with several thousand images. Some came from public sources, others were newly annotated by the researchers. The “Austrian Highway Traffic Sign Data Set (ATSD)“, which was created in the earlier SafeSign research project, proved to be particularly valuable.
Model training
Based on this data set, the team trained a model that fulfills both speed and accuracy requirements. The detection model provides the positions of the traffic signs in each video frame as bounding boxes as well as their class affiliation, such as “give way” (see also Figure 2). The model thus laid the foundation for exact spatial localization.
Figure 2: Example image with detected traffic signs. Each traffic sign is surrounded by a bounding box, and the confidence of the model (here 100%) and the class are also displayed.
Point pairing & 3D position estimation
A stereo camera system allows the depth of a point in space to be estimated – provided that the corresponding position in both images is known. For this purpose, areas of both images are compared to identify pixel-precise correspondences (see Figure 3). This allows the distance of the points between the left and right images to be calculated – the disparity (in pixels). A familiar example of this is human depth estimation: our eyes are at a constant distance from each other and therefore take in slightly different images. If we look at a finger and alternately close the left and right eye, we see that the finger changes its relative position depending on the distance to the finger – the further away, the less the shift. This shift is the disparity that our brain uses to determine the distance of the finger.
As the distance between the cameras (the baseline) and the camera properties are known in a stereo camera system, the disparity can be converted into a distance. And as soon as this relative position to the camera is determined, the real-world coordinates can also be calculated – provided the GPS position of the camera is known, as is the case with the RoadStar Truck.
Figure 3: Matching is used to identify pixel-precise positions in the left and right images.
Spatial grouping
In the next step, all instances of the same traffic sign are then grouped together. This is necessary because each traffic sign is recorded several times as it passes by. Each one must of course be reliably recognized, especially if there are several identical traffic signs in the image. The estimated real-world coordinates are used for this purpose, which can also be used to identify outliers that have been incorrectly located (e.g. due to incorrect point pairing caused by partially obscured signs).
Text recognition
In a final step, traffic signs that contain information in text form are considered. In order to extract any text, text recognition models for Optical Character Recognition (OCR) are used. There are already many pre-trained models for this, such as tesseract, but also vision language models such as Florence-2, which deliver very good results with appropriate pre-processing. See Figure 4 for an example of text extraction on km panels along the road, which are particularly challenging due to their small size.
Figure 4: Examples of OCR, the recognized text is displayed above the image section.
Output of detection data & visualization
All steps together then provide a pipeline that can automatically detect and locate existing traffic signs using any number of videos. The generated data is then available for visualizations, but also for the identification of problematic traffic signs. And – most importantly – for improving the position data of traffic signs in the country’s road databases.
Project partners
Project details
Project short title: SIGNDETECT
Long project title:Automated traffic sign recognition for road administration
Project partner:
Province of Upper Austria, Directorate for Road Construction and Transport