(R)Evolution of Language Models – ChatGPT
Answers to the most important questions about the artificial intelligences ChatGPT, Bard and co.
by Sandra Wartner, MSc
In recent weeks, everything has revolved around the new artificial intelligences (AIs) of the big players. Since the publication of OpenAI’s chatbot revolution ChatGPT at the end of November 2022 (see OpenAI page), the language model has been in a research and feedback phase that is accessible to everyone and has thus aroused public interest. With over 100 million users in January, the versatile functions and application scenarios that AI has to offer have become apparent. It helps with everyday and professional writing tasks such as shopping lists or creative marketing texts, provides suggestions for planning birthday parties, writes poems and song lyrics or helps with programming tasks.
In response to the release of ChatGPT, Google also announced its own solution, Bard, at the beginning of February. China also wants to get in on the action as another competitor and is planning to end the test phase in March with Ernie from Baidu. How the language models will fit into our everyday lives and support us is not yet entirely clear. The fact that a rethink is necessary and that the professional world will also adapt accordingly cannot be denied either.
But what is actually behind the technology surrounding the new artificial intelligences?
Table of contents
- Another milestone for the AI landscape
- How can I try ChatGPT for myself?
- How reliable are the models’ answers and what are their limits?
- Welches Potenzial für Geschäftsanwendungen verbirgt sich hinter den Technologien?
- Sources
- Author
This technical paper refers to a state of knowledge as of 22.03.2023. Subsequent changes or innovations are not taken into account.
Another milestone for the AI landscape
The underlying technology is Natural Language Processing, NLP for short (see one of our technical papers on NLP) and enables machines to process human language and to represent the knowledge in the form of (language) models. The publication of the Transformer architecture (see also [1], or another technical paper) in 2017 provided a significant milestone in this regard, driven by advances in the field of Deep Learning, the availability of large amounts of training data and increased computing power. In order to learn language representations, huge amounts of text data are provided to the language model in the pre-training phase. At this point, the model does not yet have any information about concrete tasks such as translating texts or evaluating information, and must learn these in the subsequent fine-tuning phase with the help of an annotated data set.

We have already experienced the imitation of natural conversations in the form of conversational AI via virtual assistants such as Siri and Alexa in recent years, but the new generation is even better at simulating human interactions. Anyone who has followed the media closely in recent years will have come across news about the ChatGPT predecessor models GPT-2 (2019) and GPT-3 (2020) time and again. GPT is an acronym for Generative Pretrained Transformer, and – as the name suggests – uses the aforementioned Transformer architecture to generate a human-like text response based on a textual conversation prompt that matches the context and topic. The models were developed by OpenAI, a US artificial intelligence research company, and are among the largest neural networks to date.
Chat-GPT is a fine-tuned version of GPT-3 and belongs to the GPT-3.5 family. With 175 billion parameters, it is one of the most powerful state-of-the-art language models. It has been trained on a huge amount of different text data from websites, articles and books to perform tasks such as writing, analysing and summarising or rewriting texts, but also to write and analyse programming code in different programming languages. ChatGPT works best in English, but can also handle other languages. Microsoft, as one of the main backers of the integration of the technology in the Bing search engine, has made another billion-dollar investment (see also Microsoft’s blog post), and it may well be that some functions will also be found in Outlook or Word in the future. The use of the Bing chatbot was first restricted at the beginning of the launch phase after the model showed inappropriate behaviour (including declarations of love, threats).
Google has also announced its own chatbot Bard (see also Google blog post). This is based on the Google language model LaMDA (Language Model for Dialogue Applications), which was mainly trained on texts and dialogues. One of the biggest differences at the moment is that Bard – in contrast to ChatGPT’s knowledge limit until 2021 – obtains information from the web. Bard is also currently still in the test phase, but only for a selected test group.
How can I try ChatGPT for myself?
To test the capabilities of ChatGPT yourself, an OpenAI account is required [link to ChatGPT]. Via a dialogue window in the browser, a kind of chat with the model is created, whereby one can follow the writing of the answers in real time.
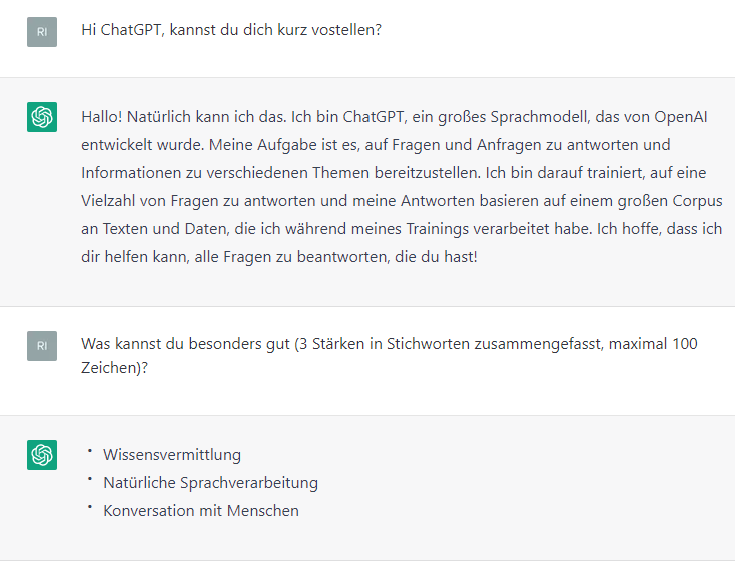
Those who are curious may have to be patient, as there are always stability and capacity problems due to the high demand. The use of ChatGPT is free of charge in the current development phase, but there are already initial cost models such as ChatGPT Plus (link to ChatGPT Plus), which should enable stable access to the model even at peak times. Since the data entered will be analysed, among other things, for the further improvement or evaluation of the model, it is important not to enter any sensitive and personal data.
How reliable are the models’ answers and what are their limits?
ChatGPT delivers impressive performance at first glance. The conversation seems so (frighteningly) natural, as if you were chatting with a human person. However, the capabilities also have certain limits [see description by OpenAI].
No hasty leap of faith
Even if the model answers sound very plausible, they are not always correct. ChatGPT tends to disguise ignorance by always generating an answer, and guesses at the intention behind ambiguous queries. Partly freely invented facts or sources (fake news) by ChatGPT and the authorship of the answers are extremely difficult to verify. Therefore, it is always necessary to critically question the credibility of the information returned and, for example, to check its correctness with additional research.
Nothing left to chance?
The wording of the input also has a significant influence on the answer that the model gives. So it can happen that ChatGPT cannot (satisfactorily) answer a certain question, but if it is rephrased, it answers appropriately.
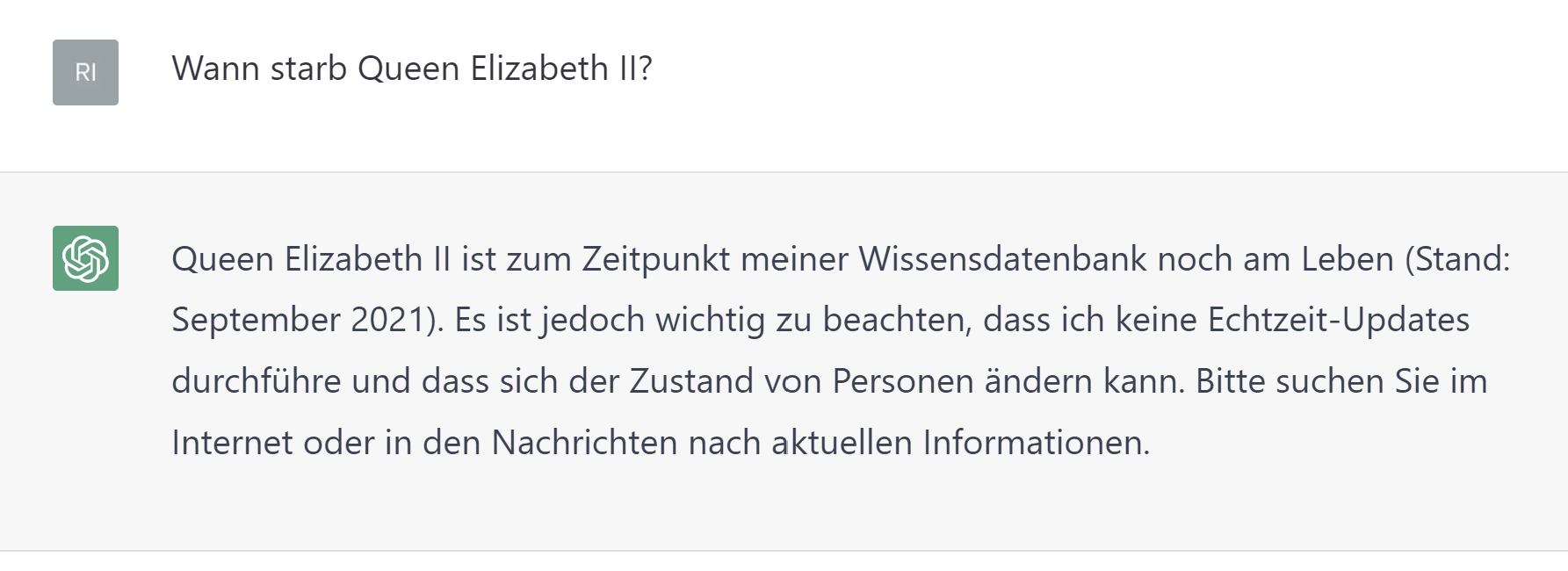
Not on the pulse of time
As there is no access to real-time data and the training data only extends to 2021, there is no guarantee that the information provided is up-to-date.
Responsible use of AI systems
Since it is not possible to check every single text with the necessary masses of training data, a language model can, among other things, learn and reproduce social or historical prejudices and stereotypes and thus cause numerous ethical problems. This problem was already evident in 2016 with Tay, a chatbot from Microsoft, which had to be taken offline again after less than 24 hours because it had turned into a racist and sexist chatbot (see also blog post by The Verge). Taking precautionary safety measures when using (and as far as possible also training) these models is therefore absolutely necessary. Mechanisms have also been built into ChatGPT to prevent inappropriate requests from being answered as a rule.
Anyone using AI models should also have an understanding of how the model arrived at this answer in order to be able to use it responsibly (see also technical paper on Explainable AI and Trust in AI). OpenAI is well aware of this issue and is trying to create more transparency regarding their intentions and progress, as well as making the finetuning process more understandable and controllable [see OpenAI blog post].
What is the potential for business applications behind the technologies?
The latest achievements in the advancement of NLP technologies are opening new doors and shaping the future of artificial intelligence and its applications. In order to be able to use the technologies responsibly and beneficially, adaptations must be made for new areas and the individual needs of the individual sectors. We, RISC Software GmbH, are specifically concerned with the sustainable use of NLP technologies in practical applications (see also the article on Natural Language Understanding) and create individual solutions for our customers. The developed AI systems support and complement the skills of the domain experts in carrying out their demanding activities.

Transformer models have also been an integral part of our projects for several years and are often part of a successful problem solution in the NLP projects. With these positive experiences, we would like to go along with the next technology step and explore the application possibilities and limits of the new technologies.
In recent years, we have repeatedly encountered similar challenges. Often there is no or not enough training data available, which has to be manually created and annotated with high human effort in order to be able to train models specifically on a task (unless, fortunately, public datasets are available that happen to represent the data situation sufficiently well). While this step is unlikely to ever be fully automated, the new models could be used for pre-annotation and corrected and augmented by humans as supervisors in a much less involved process or used for rapid prototyping. Also in NLP tasks such as information extraction, models like ChatGPT could be used (with some post-processing and integration effort) as another component of a model ensemble.
Language models such as ChatGPT are not yet fully developed, and their use must be well considered and decided for the individual use case with regard to data protection, cost/benefit factor, API dependencies, explainability and transparency, among other things.
There are currently many organisations and companies that approach us with concrete ideas for process improvement or further optimisation of their products through NLP assistants. RISC Software GmbH is happy to support and accompany its customers from the idea to the integration [see more about our competences in the field of NLP].
Sources
[1] Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
Contact
Author

Sandra Wartner, MSc
Data Scientist