How secure chatting with sensitive company data becomes possible
by Lukas Fallmann and Sandra Wartner, MSc
Artificial intelligence (AI) is not only revolutionizing everyday life, but is also unfolding its enormous potential in the corporate environment. Workflows can be improved through the (partial) automation of tasks such as the creation of documents. Customer service can also be optimized through AI-supported personalization. The provision of data insights by AI systems also helps to optimize processes. Large language models (LLMs) such as ChatGPT offer a wide range of promising applications for this. At the same time, however, concerns about the handling of sensitive information (e.g. company secrets or personal data) often remain an obstacle to the widespread acceptance of these technologies. The issue of data security is usually opaque or non-existent with large providers.
Table of contents
My data, my rules: Data protection and transparency in the use of LLMs
Specific information for specific questions – Retrieval Augmentation Generation (RAG)
1) Fine tuning
2) Retrieval Augmented Generation
Evaluation of RAG systems
Outlook & conclusion
References
Read more
Authors
The rapid advances in AI have now also significantly improved the quality of publicly available model alternatives. Companies can now also use powerful models securely and specifically with company-owned data in a specially selected infrastructure. These new possibilities also ensure transparent and trustworthy use that prioritizes the protection of sensitive information. In this article, you can find out how this is possible at a technical level and what is important.
My data, my rules: Data protection and transparency in the use of LLMs
In general, a distinction can be made between open-source and closed-source models. As the name suggests, closed-source LLMs are models in which the implementation details are not publicly accessible. This has the direct consequence that it is not clearly traceable whether and how the queries and model responses entered are further used by LLM providers. However, the advantage of closed-source applications is that business processes can be improved quickly with little to no development effort.
In contrast, open source models such as those from Mistral AI offer far more transparency. Essential model information can be viewed and is therefore easier to understand. With information on the architecture and model weights (in which the learned knowledge is encoded), the model can also be further developed (trained) with company-specific data. This allows its performance to be improved for a specific use case, language or domain. The use of open source models offers many advantages in this respect, but this goes hand in hand with increased effort and the necessary technical expertise. Such models often have to be hosted in a special infrastructure with sufficient computing resources and the support effort is significantly higher.
The following table shows a comparison of selected functions:
Function
Closed Source
Open Source
Transparency of model information (e.g. architecture, model weights, training data)
Not available
Publicly accessible
Data protection
Depending on the security precautions and logging mechanisms of the providers
Full transparency and control over data security thanks to specially implemented security measures
Personalization
Limited customization options (often restricted by prompt engineering)
Can be adapted as required (e.g. through further model training)
Development effort
Usually low setup and configuration effort
Higher initial outlay, may have to be hosted yourself
Costs
Ongoing license costs (mostly pay-per-use)
No ongoing license costs, but (acquisition) costs in the form of infrastructure or computing resources (on premise, cloud GPUs,…)
Examples
ChatGPT (OpenAI), Gemini (Google)
Mistral or Mixtral (Mistral-AI), Phi3 (Microsoft), Llama3 (Meta-AI)
Specific information for specific questions – Retrieval Augmentation Generation (RAG)
LLMs are excellent at processing questions and tasks. However, native models such as ChatGPT or Gemini usually reach their limits when it comes to answering company-specific questions. LLMs are limited to the information with which they have been trained. There are two different approaches to enable the retrieval of company-specific information.
1) Fine tuning
The computationally intensive option is to further train an existing open source model with internal company information (finetuning). Finetuning allows the model to incorporate domain-specific knowledge, such as medical terms, into its vocabulary. However, this is costly and inflexible, as new information can only be added by retraining and is particularly problematic if information changes frequently.
2) Retrieval Augmented Generation
More flexibility can be achieved using “Retrieval Augmented Generation” (RAG for short) [1], whereby this approach stores the knowledge to be integrated in an external data store that can be adapted at any time. Based on a query to the LLM, the relevant information is extracted from the knowledge base in a preliminary step (“retrieval”) and made available to the LLM as context (“augmented”) to answer the question (“generation”). For this process, it is not necessary for the LLM to have been trained with the data in advance.
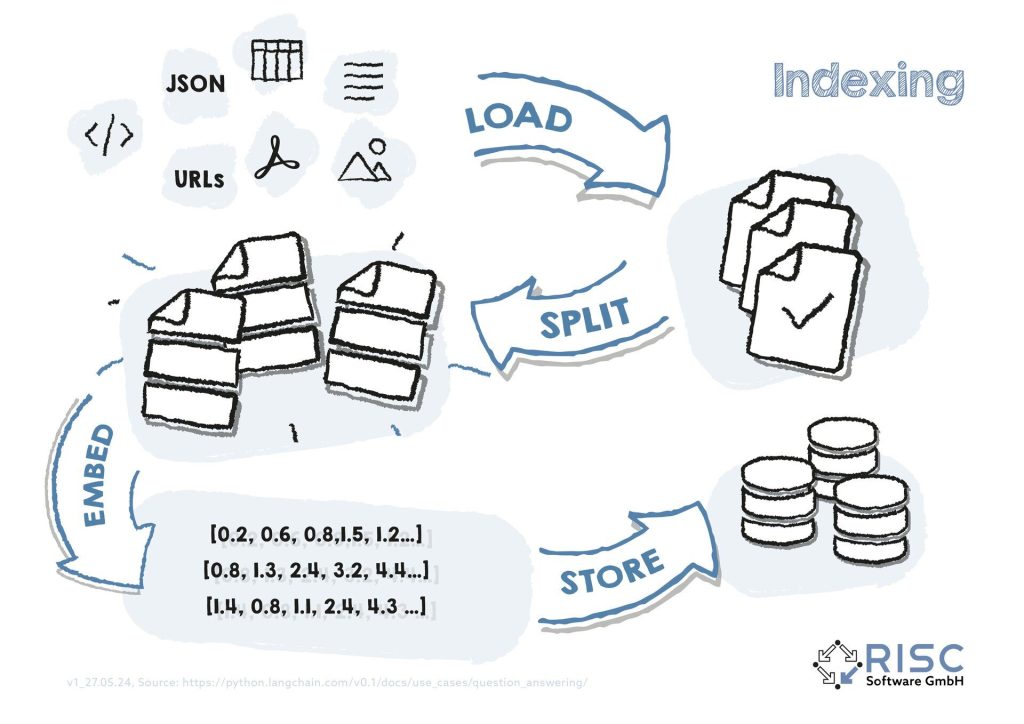
The knowledge base is built up via the indexing process (see also Fig. 1). During indexing, each individual document (e.g. text, HTML, PDF files) is loaded (“load”) and prepared in such a way that smaller, semantically coherent sub-documents are created (“split”). Next, a machine-readable numerical representation (a vector or so-called “embedding”) of the partial documents is created (“embed”) using a separate machine learning model. This “embedding” contains relevant, machine-readable information and is stored in a special vector database (“store”).
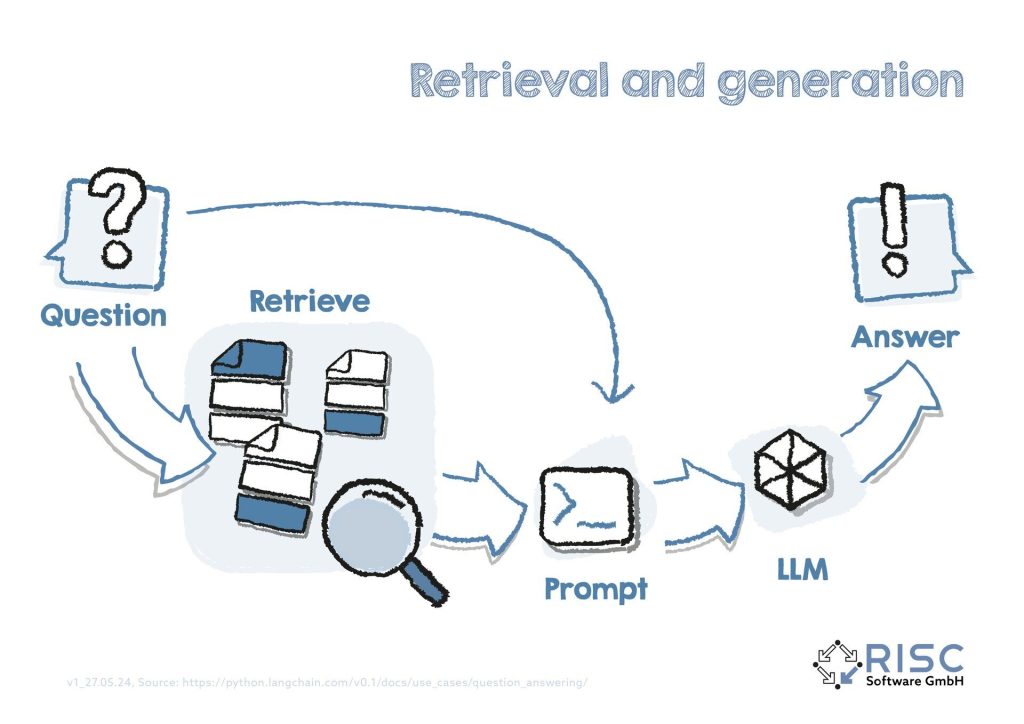
Figure 1: When a question is submitted to the RAG system, it must also be converted into a machine-readable embedding. With the help of algorithms for calculating similarities between the question embedding and the document embeddings, the most similar documents can be quickly searched for in the knowledge database with little computational effort, the corresponding original texts can be automatically inserted into the prompt and the LLM can be called for context-based answer generation (see also Figure 2).
Figure 2: The implementation of such a system requires a great deal of initial effort, as there are numerous adjustments to be made in order to find the optimal functionality, such as the model itself, different data sources, languages or the integration of tables or images. However, the effort often pays off very quickly and offers optimal starting conditions for further applications, such as a company-internal Q&A bot. The knowledge base is formed by company-relevant documents, which can be kept synchronized with the vector database so that the Q&A bot is always up to date with the latest knowledge.
Evaluation of RAG systems
It is in the nature of language that different formulations can have the same core statement, which also makes the automatic comparison of texts very difficult. Another challenge lies in being able to quantitatively compare individual RAG configurations with each other. Also, since the answers generated by the LLM are rarely clearly wrong or correct, a standardized evaluation method with clearly defined metrics is required.
Question
LLM answer
Actual answer
Answer Correctness
Who is the CEO of RISC Software GmbH?
Wolfgang Freiseisen is CEO of RISC Software GmbH.
Wolfgang Freiseisen is CEO of RISC Software GmbH.
1.0
Who is the CEO of RISC Software GmbH?
Max Mustermann is CEO of RISC Software.
Wolfgang Freiseisen is CEO of RISC Software GmbH.
0.16
Who is the CEO of RISC Software GmbH?
Wolfgang Freiseisen is Managing Director of RISC Software GmbH.
Wolfgang Freiseisen is CEO of RISC Software GmbH.
0.99
Outlook & conclusion
RAG can be used to implement a number of company-specific use cases. As with all AI-based systems, the quality of the answers generated in RAG systems is heavily dependent on the configuration and the quality of the data provided. Clean data quality management pays off, as incorrect information or contradictions in the knowledge database often not only lead to poorer quality model responses, but also often creep unnoticed into other processes (see also [3] and [4]).
Knowledge can also be extended to other sources of information with the help of so-called “agents”. Agents are advanced AI systems that have been developed for the creation of complex texts that require sequential reasoning. Agents can intelligently forward specific tasks to other expert systems and interfaces that are most suitable for a specific query or task. For example, the query “Search the web for RISC software” could be forwarded to a web search component or a query to solve a complex mathematical problem could be forwarded directly to a specially trained model. Agents can also be used in combination with evaluation tools such as Ragas to regenerate low-quality answers. Such tools will make it even easier to optimize business processes in the future.
References
[1] https://arxiv.org/abs/2312.10997 Gao, Yunfan, et al. “Retrieval-augmented generation for large language models: A survey.” arXiv preprint arXiv:2312.10997 (2023).
[2] https://arxiv.org/abs/2309.15217 Es, Shahul, et al. “Ragas: Automated evaluation of retrieval augmented generation.” arXiv preprint arXiv:2309.15217 (2023).